机器人圈过去三年最大的迷茫,是不知道自己的"GPT时刻"长什么样。Jim Fan在Sequoia AI Ascent 2026给的答案非常直接:别想了,抄LLM的作业。
LLM从GPT-3到o1只用了六年,分三个阶跃:
| LLM | 机器人 |
|---|---|
| Next-token prediction(GPT-3) | 视频世界模型预测下一帧 |
| SFT(InstructGPT) | Action fine-tuning |
| RL(o1) | Physical RL,最后一公里 |
| Coding environment | 神经物理引擎 |
| Kaplan scaling law | Dexterity scaling law |
这套对齐他叫 The Great Parallel。这不是一句口号,每一行映射背后都有一个具体的technical bet,每一个bet都对应一类商业机会。
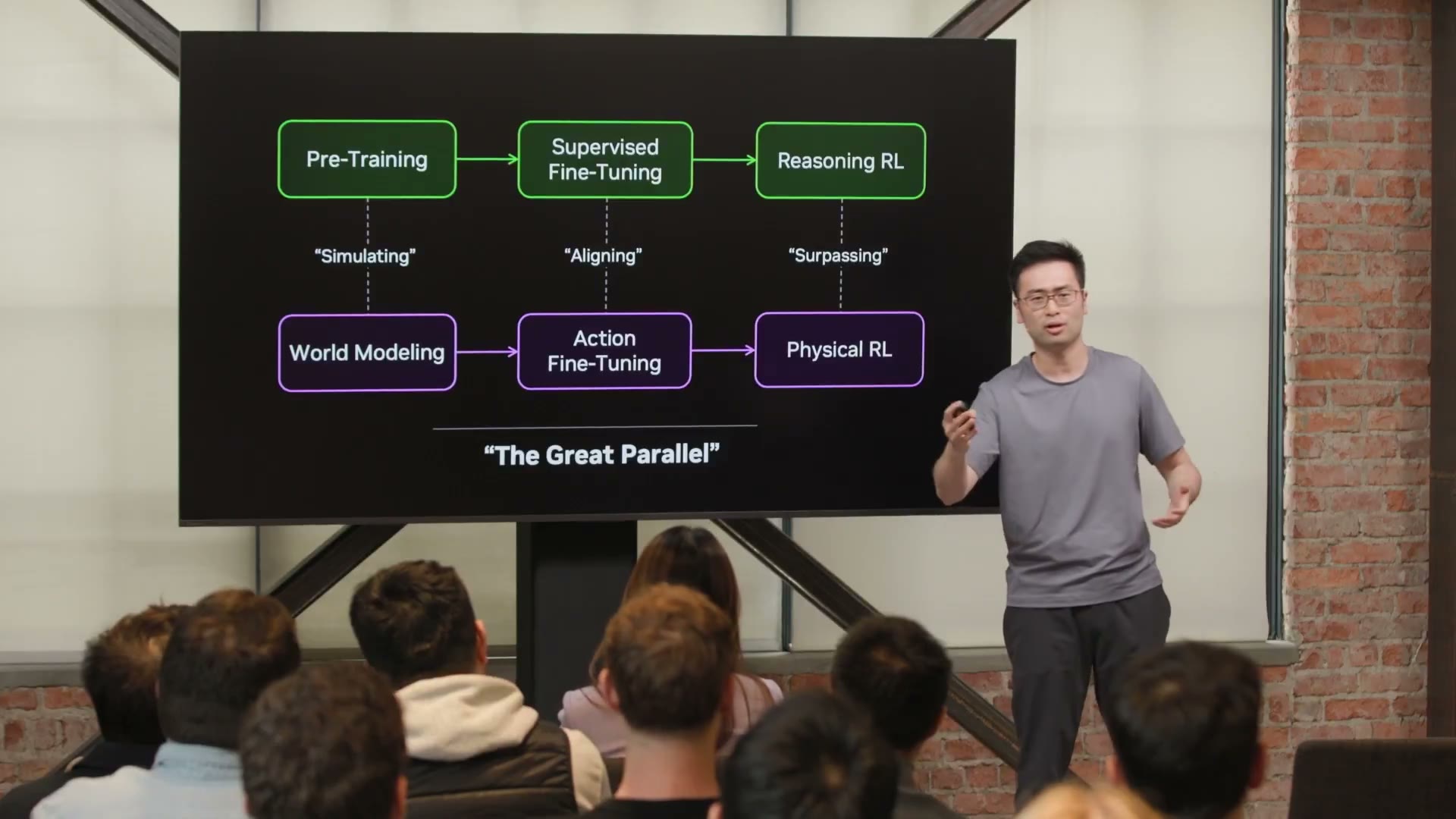 Jim Fan的"The Great Parallel"原图。上排是LLM三步函数,下排是机器人的同构版本:World Modeling(simulating) → Action Fine-Tuning(aligning) → Physical RL(surpassing)。
Jim Fan的"The Great Parallel"原图。上排是LLM三步函数,下排是机器人的同构版本:World Modeling(simulating) → Action Fine-Tuning(aligning) → Physical RL(surpassing)。
Insight 1:VLA是错的范式,问题在"参数分布"
过去三年的主流是 VLA(Vision-Language-Action),π₀、GR00T N1、OpenVLA、RT-2 都属于这一流派:拿预训练好的VLM,焊一个action head上去。
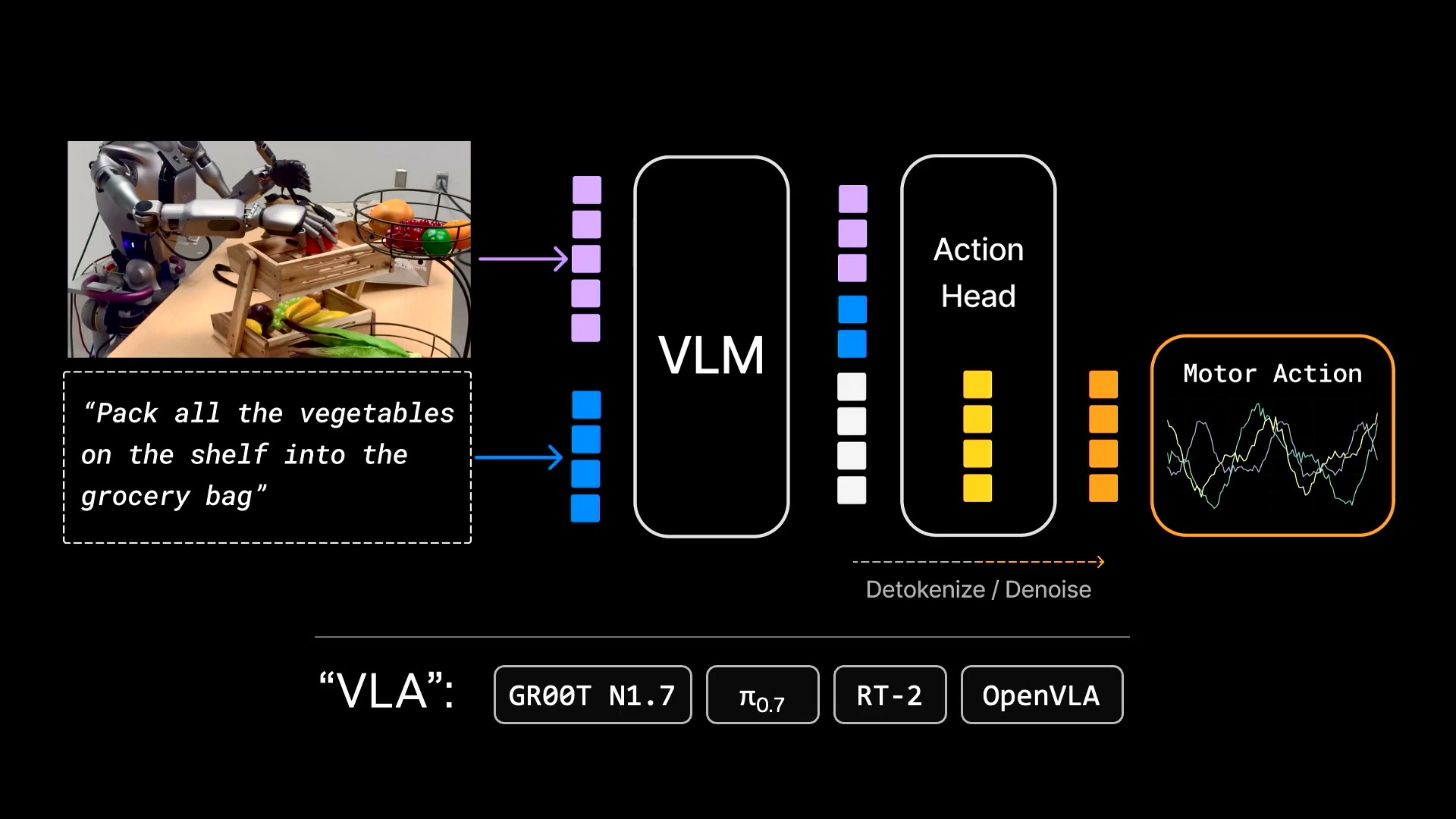 VLA的标准架构:把一个VLM主体加上Action Head + Detokenize/Denoise出马达动作。语言token塞了一堆,动作只占尾巴一小撮。
VLA的标准架构:把一个VLM主体加上Action Head + Detokenize/Denoise出马达动作。语言token塞了一堆,动作只占尾巴一小撮。
这套方法的隐含假设是:语义理解可以迁移到物理控制。
这个假设其实站不住脚。VLA的参数分布是语言 » 视觉 » 动作,绝大部分容量在编码"名词"(cat、cup、Taylor Swift),物理动力学得到的容量微乎其微。结果就是模型能认出"把可乐罐移到Taylor Swift照片上"里的所有名词,但执行"把鸡蛋滚到边缘但不掉下去"这种纯物理任务就抓瞎。
认了一个名词 ≠ 学会了物理。 语言领域的scaling帮不上物理动词。
真正的"机器人基础模型"不会从VLM增量演化出来,它需要一个重新设计的、视觉和动作都是头等公民的架构。这就是 WAM(World Action Model)。
商业含义:今天估值最高的几家做"VLA-style robot foundation model"的公司,技术路径需要重估。在VLA上堆data不会通向AGI,只会得到一个更会描述物理的语言模型。
Insight 2:视频生成slop里藏着第二个预训练范式
视频生成模型(Veo、Sora)现在被当作消费玩具:猫弹班卓琴、狗狗哲学、AI广告。但有一个事实被严重低估:
这些模型在预测下一帧的过程中,自发学会了物理。
Veo 3的生成里,重力、浮力、光影、反射、折射全部涌现,没人写过一行物理代码。甚至visual planning也涌现了,它解迷宫的方式是直接在像素空间跑前向模拟(详见 Wiedemer et al., 2025 "Video models are zero-shot learners and reasoners")。
 Jim Fan:第二预训练范式就是AI video slop。猫的奥运跳水、猫弹班卓琴——看起来像消费玩具,本质是模型在像素空间里学物理。
Jim Fan:第二预训练范式就是AI video slop。猫的奥运跳水、猫弹班卓琴——看起来像消费玩具,本质是模型在像素空间里学物理。
这件事的逻辑结构和GPT-3完全一致:压缩即智能。在文本上next-token prediction涌现出推理;在像素上next-frame prediction涌现出物理直觉。
 Visual planning也涌现了:Veo 3靠直接在像素空间跑前向模拟来解迷宫。"如果你不看,几何就是可选的"——这就是著名的physics flop现象。
Visual planning也涌现了:Veo 3靠直接在像素空间跑前向模拟来解迷宫。"如果你不看,几何就是可选的"——这就是著名的physics flop现象。
不完美的地方反而最有信息量。Veo会"省略不被观察的几何":你不看的时候,物体的背面是不存在的。这不是bug,是模型在用最小描述长度逼近世界,人类大脑其实也这么干。
商业含义:
- 视频生成不只是娱乐。任何拥有大规模视频生成模型的公司(OpenAI、Google、Runway、快手、字节),手上的资产同时也是机器人预训练的基底。这条交叉性是被严重低估的。
- "动作token化"是下一波技术差。运动控制信号是高维连续信号,结构上和像素接近,可以被联合渲染。能把action seamlessly塞进生成模型token流的团队,就掌握了WAM的核心架构。NVIDIA叫它Dream Zero。
Insight 3:Teleop已死,sensorized human data上位
机器人圈过去三年最大的钱坑是teleop。VR头显、低延迟串流、复杂rig,投入巨大。但有一个硬天花板:
\[\text{Teleop 数据量} \leq 24 \text{ 小时} \times \text{机器人数量} \times \text{天数}\]实际更惨,现实数字是3小时/机器人/天,剩下时间机器人在闹脾气。靠teleop堆出foundation model级别的数据量,物理上不可能。
破解路径是把人类身体本身变成数据采集器,分三代演化:
 UMI / DexUMI的核心idea:把机器人的末端执行器戴在人手上,让人类身体直接变成数据采集器,机器人本体踢出循环。
UMI / DexUMI的核心idea:把机器人的末端执行器戴在人手上,让人类身体直接变成数据采集器,机器人本体踢出循环。
- UMI(夹爪戴在手上)(Chi et al., RSS 2024):把机器人末端执行器从机器人本体上剥离,人手直接采数据。已孵化两家独角兽。
- DexUMI(五指外骨骼):扩展到22自由度灵巧手。比同一个PhD做teleop更快、更准、更便宜。
- EgoScale(纯第一视角视频):99.9%训练数据来自野外egocentric video(Project Aria 这类数据源),零机器人数据预训练 + 4小时teleop微调(< 0.1%训练量)。
EgoScale最关键的不是"用人类视频训机器人"(很多人在做)。关键是它发现了dexterity scaling law:预训练小时数和validation loss之间,干净的log-linear关系。距离Kaplan那篇LLM scaling law论文整整六年。
这才是机器人版的"信仰拐点"。一旦scaling law被独立复现,整个领域会进入军备竞赛:
- 谁掌握第一视角视频源(Aria、Vision Pro、智能戒指、所有wearable),谁就是机器人界的Common Crawl
- 数据采集硬件(UMI/DexUMI类)会出现"五年内十家独角兽"
- Teleop被边缘化,它仍有微调价值,但不再是核心产能
第一视角视频源是这条机会链上唯一一个已经能用美股下注的环节(数据采集硬件都还在私募阶段)。四个最直接的卡位玩家:
特别注意类比的精度:Jim Fan把它对标FSD,Tesla车主开车时完全无意识地贡献数据。能让数据采集"消失在背景里"的硬件形态才会赢。今天的UMI还是侵入式的,它是过渡形态,不是终态。
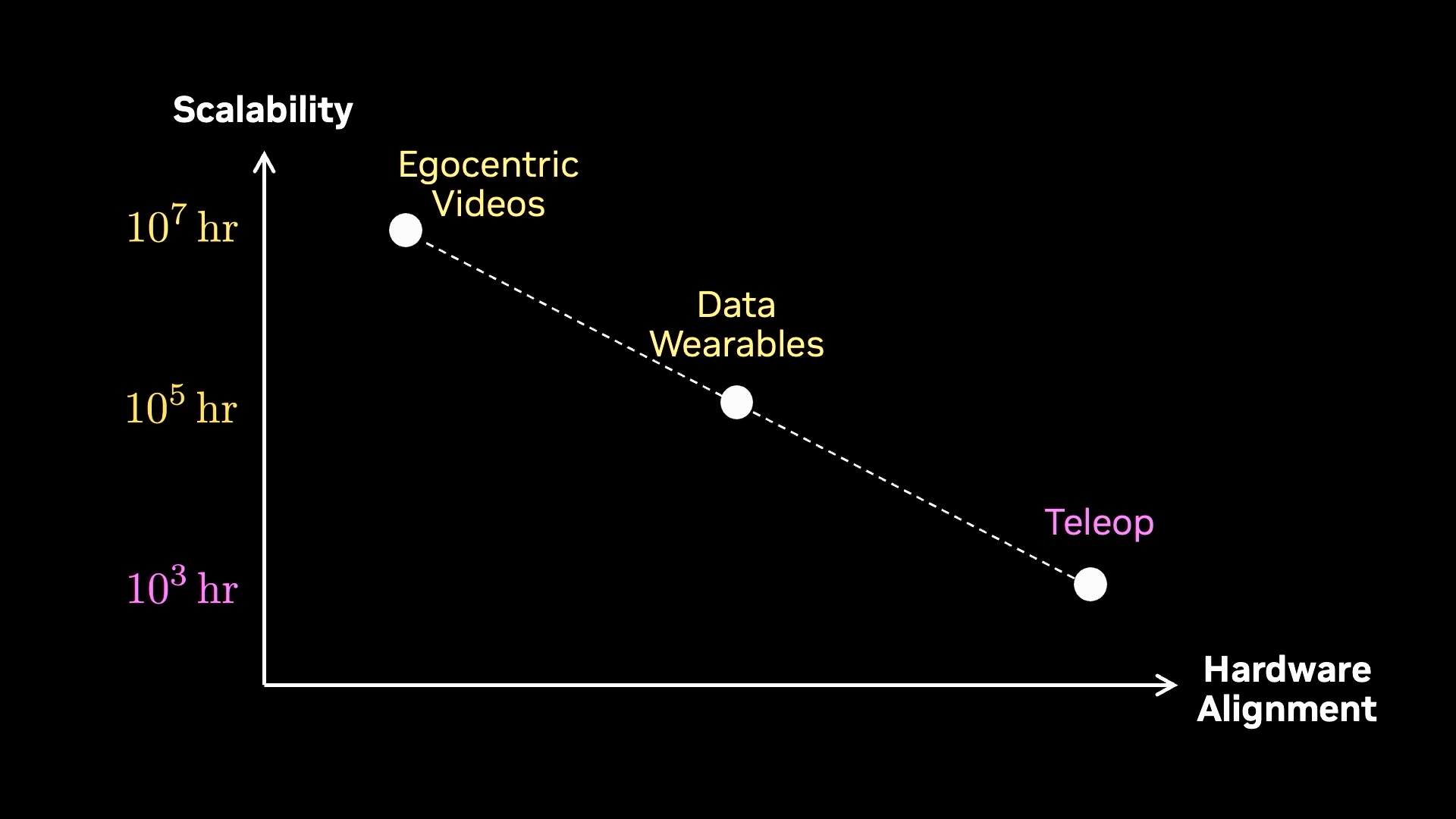 Jim Fan的数据策略全景图。横轴是与硬件的对齐度,纵轴是scalability(log坐标):Teleop = 10³ hr,Data Wearables = 10⁵ hr,Egocentric Videos = 10⁷ hr。差出四个数量级。
Jim Fan的数据策略全景图。横轴是与硬件的对齐度,纵轴是scalability(log坐标):Teleop = 10³ hr,Data Wearables = 10⁵ hr,Egocentric Videos = 10⁷ hr。差出四个数量级。
Insight 4:算力 = 环境 = 数据
LLM RL的瓶颈是coding environment,OpenAI、Anthropic花上亿美金买环境。机器人RL的瓶颈更狠:100万个真机环境物理上不可能。
中间方案是Real-to-Sim-to-Real(iPhone扫一下 → 3D重建 → 经典物理仿真器 + digital cousin增强)。但它仍然依赖手写图形引擎,scale不上去。
更激进的是 DreamDojo:直接把视频世界模型当物理引擎。输入连续动作,输出实时RGB + 传感器状态,零物理方程、零图形引擎。
 Jim Fan给出的供给侧新等式:在DreamDojo范式下,算力直接转化为环境,环境直接转化为数据。整个数据/环境侧被算力化了。
Jim Fan给出的供给侧新等式:在DreamDojo范式下,算力直接转化为环境,环境直接转化为数据。整个数据/环境侧被算力化了。
这是一个供给侧的范式转移:
\[\text{compute} = \text{environment} = \text{data}\]在LLM时代,环境是人写的代码题;在机器人时代,环境本身就是一个神经网络。算力直接生产环境,环境直接生产数据。整个数据/环境的供给侧被算力化了。
商业含义:
- 这会催生 "EmbodiSim as a Service",按GPU小时计费的神经仿真器云服务。机器人版AWS。
- NVIDIA在这一层是天然赢家(既卖卡又写仿真器),但应用层会有独立机会。
- 有一个关键风险容易被忽略:reward hacking via hallucination。视频世界模型会"省略不被观察的几何",RL策略会发现"只要不看物体就能穿墙",这种漏洞在真机上是致命的。谁先解决神经仿真器的物理一致性验证问题,谁就掌握了护城河。
Insight 5:可证伪 vs 不可证伪,这套框架的真正价值
Jim Fan的路线图最值得敬佩的不是它的雄心,而是它可证伪:
- LLM next-token prediction ↔ 视频世界模型
- LLM SFT ↔ action fine-tuning
- LLM RL ↔ DreamDojo
- LLM coding env ↔ 神经物理引擎
- LLM scaling law ↔ dexterity scaling law
两年后这五条里只要有一条断了,整个框架就要修正。这比"AI将改变一切"那种宏大叙事扎实得多。
最容易断的是哪一条?我的判断是第四条,DreamDojo级别的神经仿真器还有reward hacking问题没解决。最不容易断的是第三条,sensorized human data已经在多个独立团队复现了趋势。
未来十年的商业机会图
把以上insights翻译成机会地图。
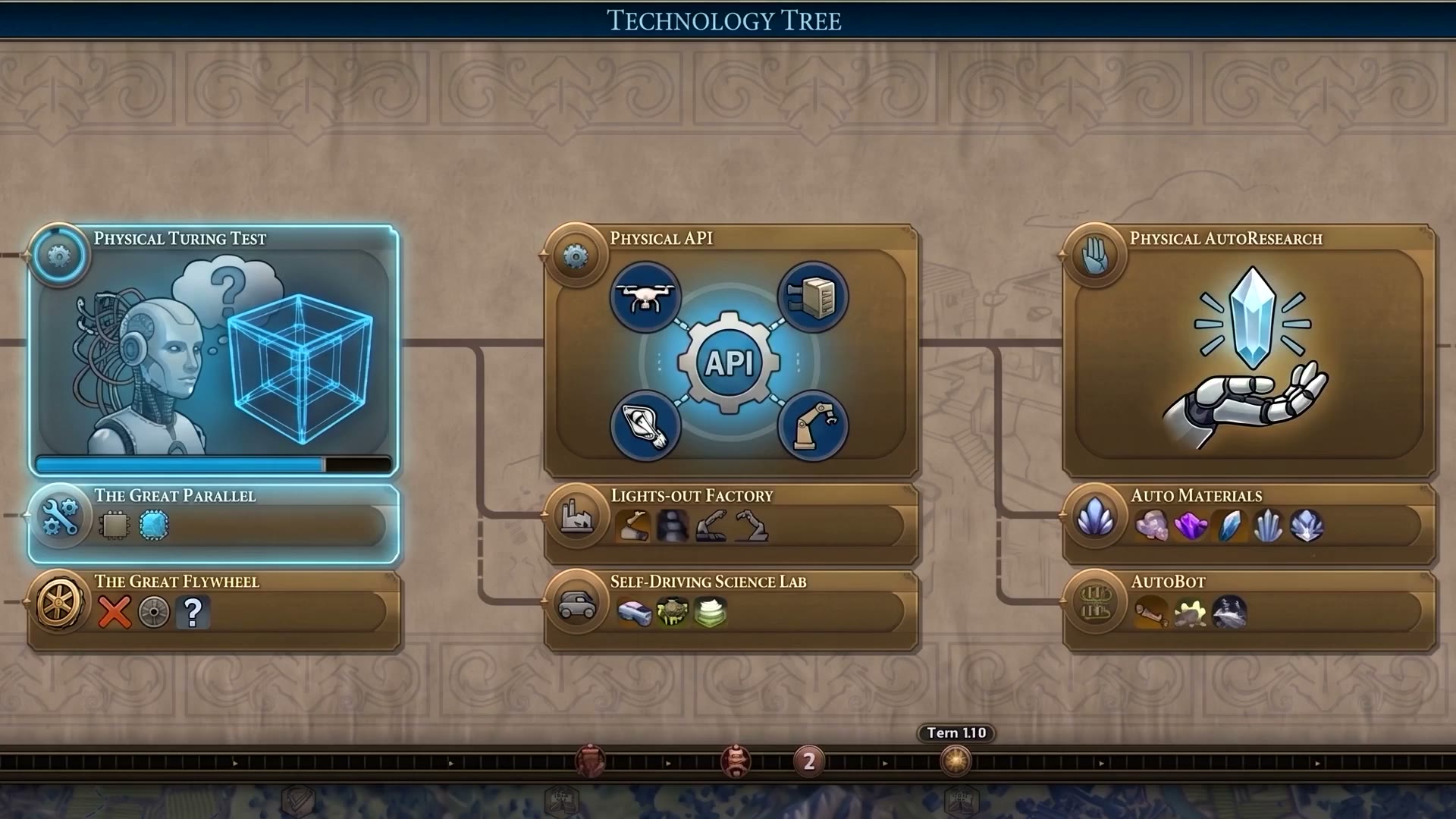 Jim Fan用《文明》游戏的科技树类比机器人路线图:Physical Turing Test(2-3年)→ Physical API(光速工厂 + 自动化湿实验室)→ Physical AutoResearch。下面六张商业牌就是在这三个里程碑的不同时间窗口上下注。
Jim Fan用《文明》游戏的科技树类比机器人路线图:Physical Turing Test(2-3年)→ Physical API(光速工厂 + 自动化湿实验室)→ Physical AutoResearch。下面六张商业牌就是在这三个里程碑的不同时间窗口上下注。
牌一:垂直全栈(短期最大价值池)
通用机器人大脑还没烤熟。短期最大价值会被垂直全栈玩家吃掉:专用硬件 + 领域数据 + 微调模型,端到端打包。仓库、手术、配送、工业检测,每个都是几十亿美元赛道。
硬件成本曲线在崩。建筑机器人三年内从10万美元跌到1.5万美元。便宜硬件 × 高效AI软件 = 商品化红利。
经验法则:别等通用大脑,做你那一行的99.9%可靠的"小脑"。99.9%不是营销数字,是部署可靠性的真实门槛。95%和99.9%之间的距离,比你想的远十倍。
牌二:WAM大脑层(长期最大蛋糕)
VLA如果真的被WAM取代,"通用机器人大脑"这个万亿级位置现在是空的。卡位需要两个能力:
- Dream Zero式零样本泛化,没学过解鞋带也能凭物理直觉做出来
- 显式3D/4D空间重构(业内已经有X-WAM的口号),视频模型再强,几何精度落地还是要解
谁先把WAM做到foundation model级别可靠性,谁就是机器人界的OpenAI。但要警惕:这一层的赢家结构很可能是寡头,和LLM一样,全球容得下2-3家。
牌三:数据基础设施(最被低估)
整个路线图最被低估的商业机会,藏在"24小时诅咒"那张slide后面:
- Sensorized wearables:UMI/DexUMI孵化了2家独角兽,五年内出10家。任何把人手变成"数据采集口"的硬件都值钱。
- 第一视角视频流的所有权:Aria、Vision Pro、智能戒指,它们最终都是机器人训练数据源。两年内人类第一视角视频成为机器人训练主食。谁拥有这些数据流,谁就是机器人界的Common Crawl。
- EmbodiSim / 模拟即服务:神经仿真器云服务,按GPU小时付费。机器人版AWS。NVIDIA有先发优势但不一定通吃。
牌四:里程碑红利
每解锁一个achievement对应一波产业海啸:
- 物理图灵测试(2-3年):服务业 + 工业机器人大规模铺开。先受益者是已经在垂直场景跑通的玩家(见牌一)。
- 物理API(2030-2035):黑灯工厂(Lights-out Factories)成为现实。最值钱的是"工厂编排层",机器人界的Kubernetes。
- 自动化湿实验室:制药/新材料R&D周期压缩一个数量级。最值钱的是垂直科学发现平台(结合proprietary生物/化学数据 + 机器人执行 + AI规划)。
牌五:高估值赛道(钱已经在跑了)
- 国防机器人:估值倍数最离谱、采购周期最短。预测:第一个500亿美元级IPO会从这条线出来。
- 人形机器人替代劳动力:全球年人工工资市场30-40万亿美元。哪怕吃掉百分之几,潜在价值在10万亿量级。Figure的Helix类系统已经在demo连续7-10小时工作。
- 关键零部件供应链:高扭矩执行器、紧凑型电机、力矩传感器、谐波减速器。人形需求一起量,整条供应链重排序。中国制造业在这一层的卡位窗口期是2026-2029,过了就锁定。
牌六:可解释性与验证(5年后的必需基础层)
世界模型是黑盒。"不看的时候几何是可选的"在生成视频里是搞笑,在工厂里是事故。任何在物理世界跑的AI都需要在统计意义上证明自己安全。
机器人版的Anthropic interpretability团队会成为下一个基础设施层。5年内这个赛道一定会出独立独角兽。容易被忽略,因为它不性感,但它是bet产业能否真正大规模部署的门票。
几个"反共识"判断
最后留几个我和主流叙事不太一样的判断:
- 人形机器人不是答案,至少不是早期答案。 第一波规模化部署一定来自专用形态:轮式底盘 + 双臂、固定工位 + 灵巧手。人形漂亮但工程负担太重,需要等到Physical API那一关。
- 机器人大模型最终会出现在中国。 不是因为算法,而是因为数据、硬件供应链、应用场景三者都在这儿。WAM层全球可能2-3家,其中至少1家来自中国。
- 2040太晚了。 Jim Fan的95%置信区间是"科技树终点"。物理图灵测试2028就会过,物理API在2032之前必然落地。差距来自指数尾部的厚度。
- 最大的赢家可能根本不是机器人公司。 而是把机器人当成"分布式末端"的应用层。比如自动化湿实验室公司本质是AI制药公司,不是机器人公司。和"iPhone时代最大赢家不是手机厂"是同构的。
"Our generation was born too late to explore the earth and too early to explore the stars.
But we are born just in time to solve robotics."