想法很好,但实操起来一直很拉胯。
JEPA训练时特别容易崩。大家不得不往上堆各种trick:EMA、stop-gradient、VICReg、辅助任务……本来应该是个很优雅的架构,结果被糊成了一堆工程补丁。
2026年3月,Mila、NYU和Brown的团队(LeCun也在作者列表里)终于拿出了一个干净的方案:LeWorldModel(LeWM),第一个能从raw pixels端到端稳定训练的JEPA世界模型。不用EMA,不用预训练编码器,不用六七个loss。就两个loss,一个超参数。
论文:Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
JEPA到底在干嘛
先回顾一下JEPA的核心思路。
传统的生成式世界模型(比如Dreamer系列)直接在像素空间做预测:给当前帧和动作,预测下一帧的图像。问题在于模型需要重建完整的像素,包括纹理、光影、背景这些跟"理解物理"没啥关系的东西。
JEPA的做法不一样:不预测像素,预测表征。
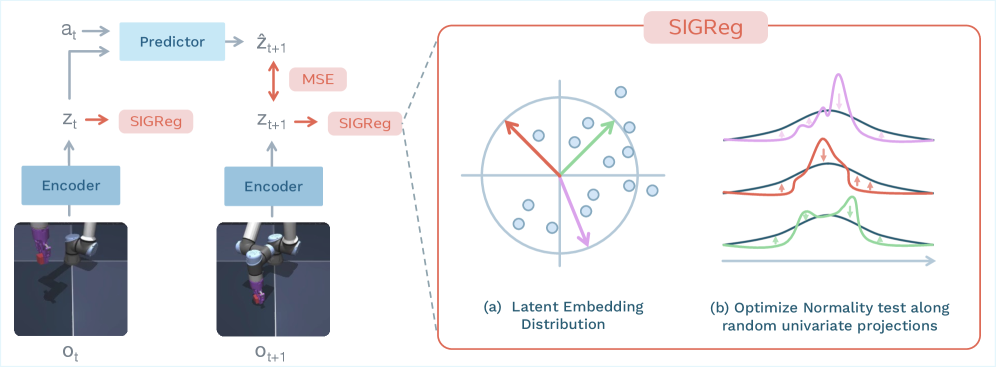 图1:LeWM的训练架构。左半部分是编码器-预测器的嵌入学习,右半部分是SIGReg正则化的工作原理:通过随机投影和正态性检验来保证嵌入分布不退化。
图1:LeWM的训练架构。左半部分是编码器-预测器的嵌入学习,右半部分是SIGReg正则化的工作原理:通过随机投影和正态性检验来保证嵌入分布不退化。
具体来说分三步:
- 编码器 $f_\theta$ 把观测 $o_t$ 映射到低维向量 $z_t$
- 预测器 $g_\phi$ 接收当前表征 $z_t$ 和动作 $a_t$,预测下一步的表征 $\hat{z}_{t+1}$
- 训练目标就是让 $\hat{z}{t+1}$ 尽量接近真实编码 $z{t+1} = f_\theta(o_{t+1})$
写成公式:
\[\mathcal{L}_{\text{pred}} = \|\hat{z}_{t+1} - z_{t+1}\|^2_2\]就是个MSE。latent space里做预测只要算192维的向量运算,不需要重建 $224 \times 224 \times 3$ 的像素。信息量压缩了大概200倍。
核心问题:表征坍缩
如果loss只有上面这个MSE,训练会怎样?
模型会直接崩掉。
这就是JEPA领域老生常谈的表征坍缩(representation collapse)。
原因不难理解:编码器和预测器是一起训练的。如果编码器学会了"偷懒",不管输入啥图都输出同一个常数向量,那预测器的活就太简单了(永远输出那个常数就行),MSE自然为零。
好比一个学生发现"答案全选A"就能拿满分。loss降到零了,但啥也没学到。
以前怎么解决的
为了对抗坍缩,前人搞出了一整套技术栈:
| 技巧 | 原理 | 问题 |
|---|---|---|
| Stop-gradient | 目标编码器不回传梯度 | 端到端训练被打断 |
| EMA | 目标编码器用上下文编码器的指数移动平均 | 引入延迟,动量系数要调 |
| VICReg | 加方差/不变性/协方差三个正则 | 多3个超参数 |
| 预训练编码器 | 直接冻结DINO/DINOv2 | 编码器没法适配下游任务 |
| 辅助任务 | 同时训练逆动力学模型等 | 增加计算开销和超参数 |
拿目前唯一的端到端方案PLDM来看,它的训练目标长这样:
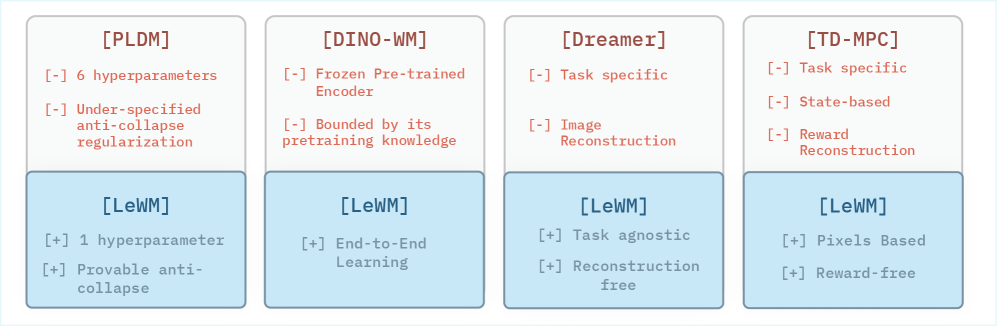 图2:各方法对比。PLDM用了7个loss(预测损失、方差/协方差正则及时序变体、逆动力学损失)和6个超参数 $(\alpha, \beta, \gamma, \zeta, \nu, \mu)$。LeWM只有1个。
图2:各方法对比。PLDM用了7个loss(预测损失、方差/协方差正则及时序变体、逆动力学损失)和6个超参数 $(\alpha, \beta, \gamma, \zeta, \nu, \mu)$。LeWM只有1个。
7个loss,6个超参数。搜索空间 $O(n^6)$。这不是在做research,这是在炼丹。
LeWM的做法:SIGReg
LeWM的核心贡献一句话就能说清:
用SIGReg正则化替掉所有反坍缩trick,实现纯端到端训练。
总loss就两项:
\[\mathcal{L}_{\text{LeWM}} = \mathcal{L}_{\text{pred}} + \lambda \cdot \text{SIGReg}(Z)\]超参数只有一个 $\lambda$(默认0.1)。
SIGReg是什么
SIGReg全称Sketched Isotropic Gaussian Regularization,做的事情是强制编码器输出的分布接近标准正态 $\mathcal{N}(0, I)$。
为什么这就能防坍缩?
想一下:如果所有嵌入都坍缩到同一个点,分布退化成delta函数,离高斯分布十万八千里。所以只要惩罚"不像高斯"的程度,坍缩在数学上就被排除了。
但192维空间里直接检验一个分布是不是高斯,计算上做不到。
Cramér-Wold定理
SIGReg巧妙地利用了一个经典结论,Cramér-Wold定理:
一个随机向量如果在所有一维投影上都是高斯的,那联合分布一定是高斯。
基于这个定理,SIGReg的做法是:
- 从单位球面 $\mathbb{S}^{d-1}$ 上随机采 $M$ 个方向 $u^{(m)}$(默认 $M = 1024$)
- 把所有嵌入 $Z$ 投影到每个方向上:$h^{(m)} = Z \cdot u^{(m)}$
- 对每个一维投影,用Epps-Pulley检验度量它跟标准正态的偏离
- 对所有投影的统计量取平均
其中 $T$ 是Epps-Pulley检验统计量,通过比较经验特征函数和标准正态的特征函数算出来:
\[T^{(m)} = \int_{-\infty}^{\infty} w(t) \left| \varphi_N(t; h^{(m)}) - \varphi_0(t) \right|^2 dt\]$\varphi_N$ 是经验特征函数,$\varphi_0$ 是标准正态的特征函数,$w(t)$ 是权重函数。
几个重要性质:
- 计算复杂度是线性的:对嵌入维度和样本数都是线性,没有维度灾难
- 梯度有界:梯度和曲率都有理论上界,训练稳定
- 充分条件:$\text{SIGReg}(Z) \to 0$ 时,Cramér-Wold定理保证联合分布收敛到 $\mathcal{N}(0, I)$
架构细节
编码器:ViT-Tiny
- 骨干:ViT-Tiny,约5M参数
- Patch size:14
- 层数:12层,3个attention head
- 隐藏维度:192
- 输出:取[CLS] token → 1层MLP + BatchNorm → 嵌入 $z_t$
为什么要加这个MLP?因为ViT最后一层有LayerNorm,会干扰SIGReg的优化。加一层投影就绕过去了。
论文也试了ResNet-18当backbone,性能差不多,说明这个方法对架构选择不太敏感。
预测器:Transformer
- 参数量:约10M
- 层数:6层Transformer,16个attention head
- Dropout:10%
- 输入:$N$ 帧历史表征序列
- 输出:自回归预测下一帧嵌入
- 动作注入:用AdaLN(Adaptive Layer Normalization)
AdaLN不是简单地把动作concat到输入里,而是让动作去调制每层归一化的scale和bias。这个做法在DiT等扩散模型里已经被验证过了。
一个值得注意的细节:AdaLN参数初始化为零。训练初期预测器接近恒等映射,有助于稳定训练。
规划:在latent space里"想象"
LeWM训练好以后,可以直接做视觉规划。给一张起始图 $o_1$ 和一张目标图 $o_g$,模型需要找出一组动作把agent从起点带到终点。
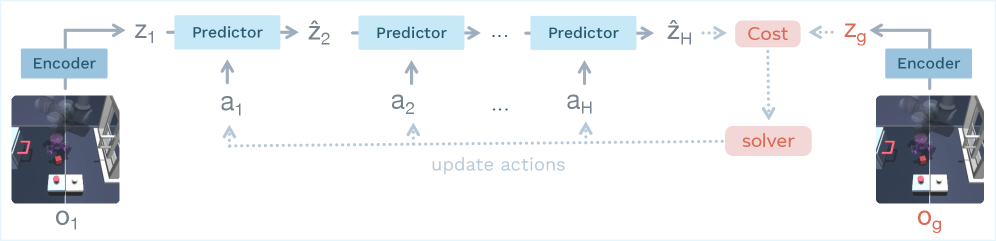 图3:LeWM的规划流程。编码器把起始和目标映射到latent space,预测器链式推演候选动作序列,CEM优化器选出最优动作。
图3:LeWM的规划流程。编码器把起始和目标映射到latent space,预测器链式推演候选动作序列,CEM优化器选出最优动作。
整个过程都在192维latent space里完成,不碰像素:
- 编码起始帧 $z_1 = f_\theta(o_1)$,编码目标帧 $z_g = f_\theta(o_g)$
- 用CEM(Cross-Entropy Method)搜索动作序列:
- 采样300条候选动作序列
- 在latent space里链式推演:$\hat{z}{t+1} = g\phi(\hat{z}_t, a_t)$
- 算末状态到目标的距离:$C = |\hat{z}_H - z_g|^2_2$
- 取top-30的elite序列,更新采样分布
- 迭代30轮
- 用MPC(模型预测控制):只执行前 $K$ 步,重新观测后再重新规划
因为都是低维运算,规划速度很快,不到1秒就能跑完,比DINO-WM快了48倍。
实验结果
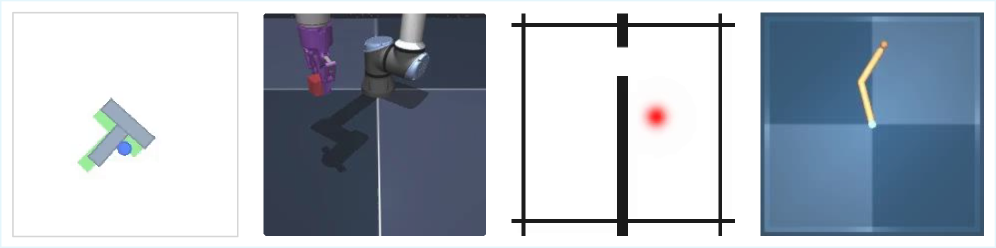 图4:四个评估环境,涵盖2D导航、2D操控和3D机器人控制。
图4:四个评估环境,涵盖2D导航、2D操控和3D机器人控制。
规划性能
先看最能体现操控能力的Push-T任务:
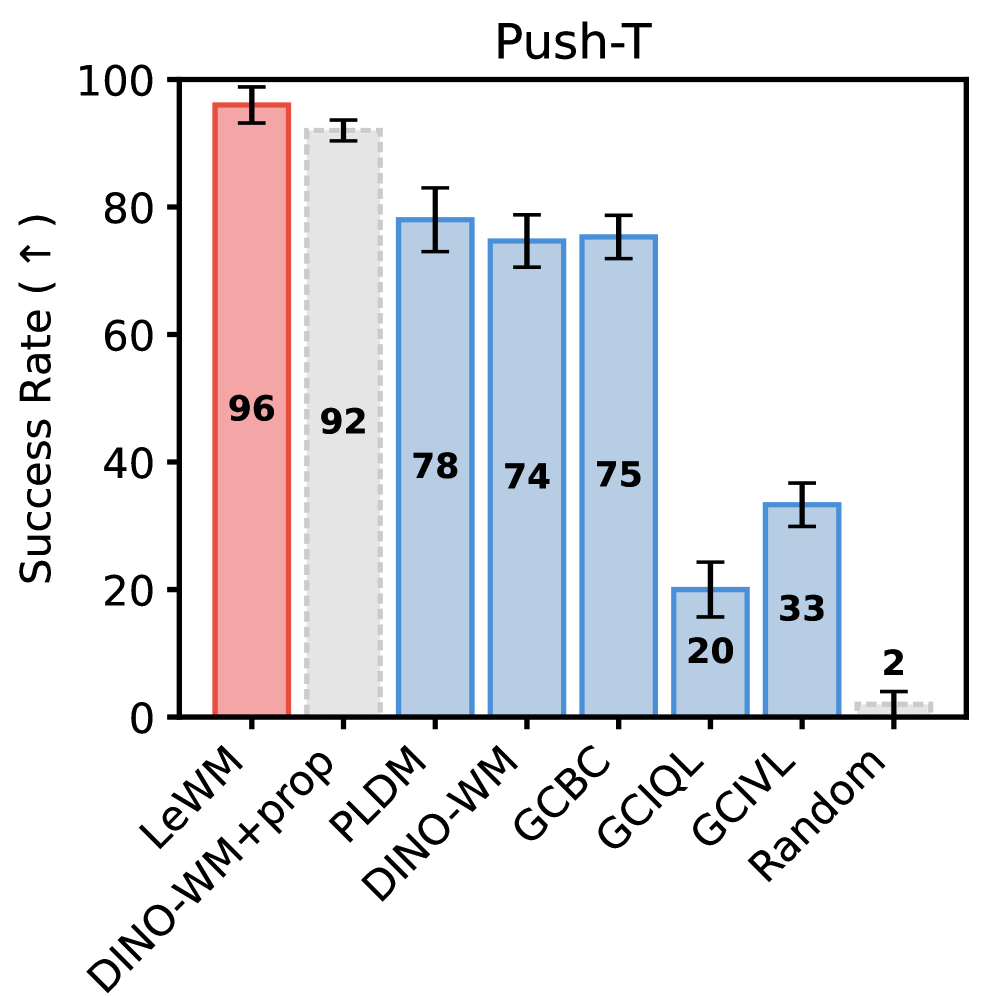 图5:Push-T任务规划成功率。LeWM(红色,96%)大幅领先所有baseline,包括用了1.24亿图像预训练的DINO-WM(74%)和7个loss的PLDM(78%)。
图5:Push-T任务规划成功率。LeWM(红色,96%)大幅领先所有baseline,包括用了1.24亿图像预训练的DINO-WM(74%)和7个loss的PLDM(78%)。
LeWM拿了96%成功率,比PLDM高18个点,比DINO-WM高22个点。DINO-WM可是用了在1.24亿张图上预训练过的DINOv2编码器。
各任务完整对比:
| 任务 | LeWM | DINO-WM | PLDM | 说明 |
|---|---|---|---|---|
| Push-T | 96% | 74% | 78% | 最佳 |
| Reacher | 最佳 | 次之 | 较弱 | 超过两个baseline |
| OGBench-Cube | 次之 | 最佳 | — | 3D视觉复杂,DINO预训练有优势 |
| Two-Room | 87% | 100% | 97% | 固有维度低,SIGReg的已知局限 |
Two-Room上的劣势值得说一下:这个环境就是个简单的2D导航,数据内在维度很低。SIGReg强制嵌入服从全维度高斯,在低维问题上会引入多余的约束。论文对此也做了坦诚的讨论。
规划速度
LeWM的规划不到1秒,DINO-WM要约47秒,差了48倍。原因是192维的嵌入太紧凑了,DINO-WM的token数大概是LeWM的200倍。
学到的表征有物理意义吗
一个关键问题:latent space里学到的表征,到底编码了啥?
物理量线性探测
作者用简单的线性/MLP探针从表征中预测物理量(agent位置、物块位置、物块角度)。结果LeWM全面优于PLDM,和DINO-WM打得有来有回(后者毕竟有大规模预训练加持)。
违反预期实验
更有意思的是Violation-of-Expectation实验:给模型看正常轨迹和异常轨迹(比如物体瞬移),观察模型的预测误差("惊讶程度")。
结果是LeWM对物理违规(瞬移)的惊讶信号显著更高($p < 0.01$),但对纯视觉变化(换颜色)反应不大。说明模型确实在学物理结构,而不只是在记像素pattern。
涌现特性
论文里有几个有趣的发现,都不是训练目标里显式要求的:
轨迹"拉直"
训练过程中,latent space里相邻时间步的速度向量方向会逐渐对齐,轨迹越来越"直"。没有加任何时序平滑正则,这个行为是自己冒出来的,而且比PLDM(有显式时序正则)还强。
说明模型自发学出了一种让动态预测更简单、更线性的状态表示。
从嵌入重建图像
作者在训练完成后额外训了一个轻量解码器,从192维嵌入重建视觉场景:
 图6:解码器可视化。随着训练推进(0步→200k步),192维嵌入重建出的图像从噪声逐渐变清晰。注意训练目标里根本没有重建loss,这些视觉信息是为了预测动态而"附带"学到的。
图6:解码器可视化。随着训练推进(0步→200k步),192维嵌入重建出的图像从噪声逐渐变清晰。注意训练目标里根本没有重建loss,这些视觉信息是为了预测动态而"附带"学到的。
训练时完全没有重建loss,但解码器居然能从192维向量里恢复出清晰的场景。嵌入确实捕获了丰富的视觉和物理信息。
latent space的几何结构
t-SNE可视化也能看出来:
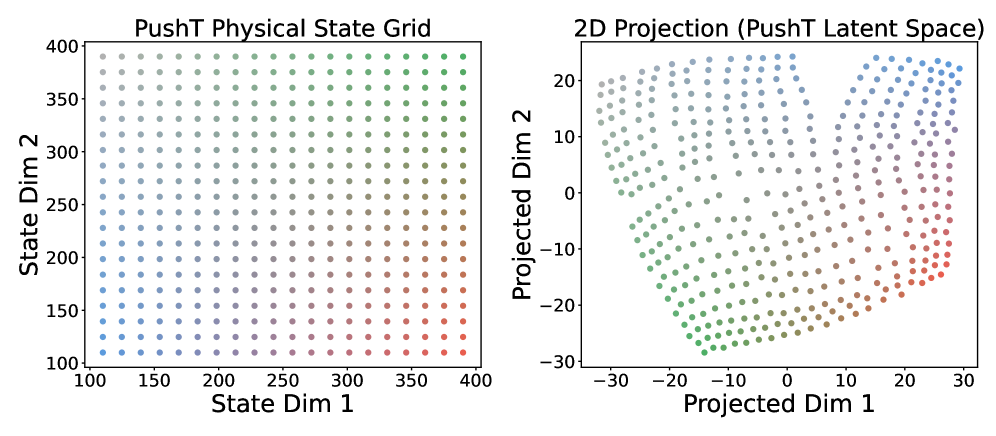 图7:Push-T任务的物理状态网格(左)和latent space投影(右)。颜色编码物理位置。latent space保持了物理空间的拓扑关系,这种保距映射是自发涌现的。
图7:Push-T任务的物理状态网格(左)和latent space投影(右)。颜色编码物理位置。latent space保持了物理空间的拓扑关系,这种保距映射是自发涌现的。
物理空间的邻近关系在latent space里被忠实地保持了下来。
预测器的"想象力"
把预测器做开环推演(给定初始状态后连续预测多步,中间不给真实观测),能直观看到模型的"想象"能力:
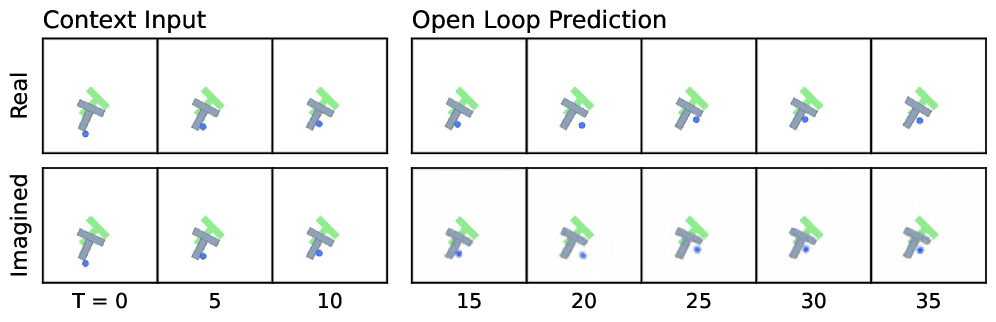 图8:开环推演可视化(用post-hoc解码器重建)。上排是真实观测,下排是模型的"想象"。Context Input是输入帧($t=0$),后面的帧完全由模型自回归生成。
图8:开环推演可视化(用post-hoc解码器重建)。上排是真实观测,下排是模型的"想象"。Context Input是输入帧($t=0$),后面的帧完全由模型自回归生成。
即使推演很多步,"想象"出来的场景仍然保持物理合理性。
总结
LeWM的意义不只是做出了一个更好的世界模型,更重要的是它对JEPA范式的验证。
之前的情况是:JEPA理论上很漂亮,但训练起来全靠hack。这让人怀疑到底是JEPA本身就有问题,还是我们没找对训练方法。
LeWM的回答很明确:JEPA没问题,问题在训练方法。用对了正则化(SIGReg),JEPA可以很简洁、很稳定地训练。
几个关键数字:
- 7个loss → 2个
- 6个超参数 → 1个
- 47秒规划 → 1秒(48倍加速)
- 15M参数,1张GPU
这意味着有一张GPU就能在几小时内训出一个能在latent space里做物理规划的世界模型。JEPA从"实验室里的概念验证"走到了"可以真正用起来"。
当然局限也很明显:视觉复杂度高的3D任务不如预训练编码器的方案,固有维度低的简单任务上SIGReg约束过强。但作为第一个真正端到端的JEPA世界模型,它打开的门比关上的多。
LeCun一直在说"未来的AI需要世界模型"。现在他的团队证明了,这些模型确实可以干净利落地训出来。不用炼丹,靠数学就行。
参考文献:Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, Randall Balestriero. "LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels." arXiv:2603.19312, 2026.
| *项目主页:le-wm.github.io | 代码:github.com/lucas-maes/le-wm* |
 TripoSG能处理各种风格的输入——写实照片、卡通角色、概念草图——并生成拓扑完整、细节丰富的3D网格。
TripoSG能处理各种风格的输入——写实照片、卡通角色、概念草图——并生成拓扑完整、细节丰富的3D网格。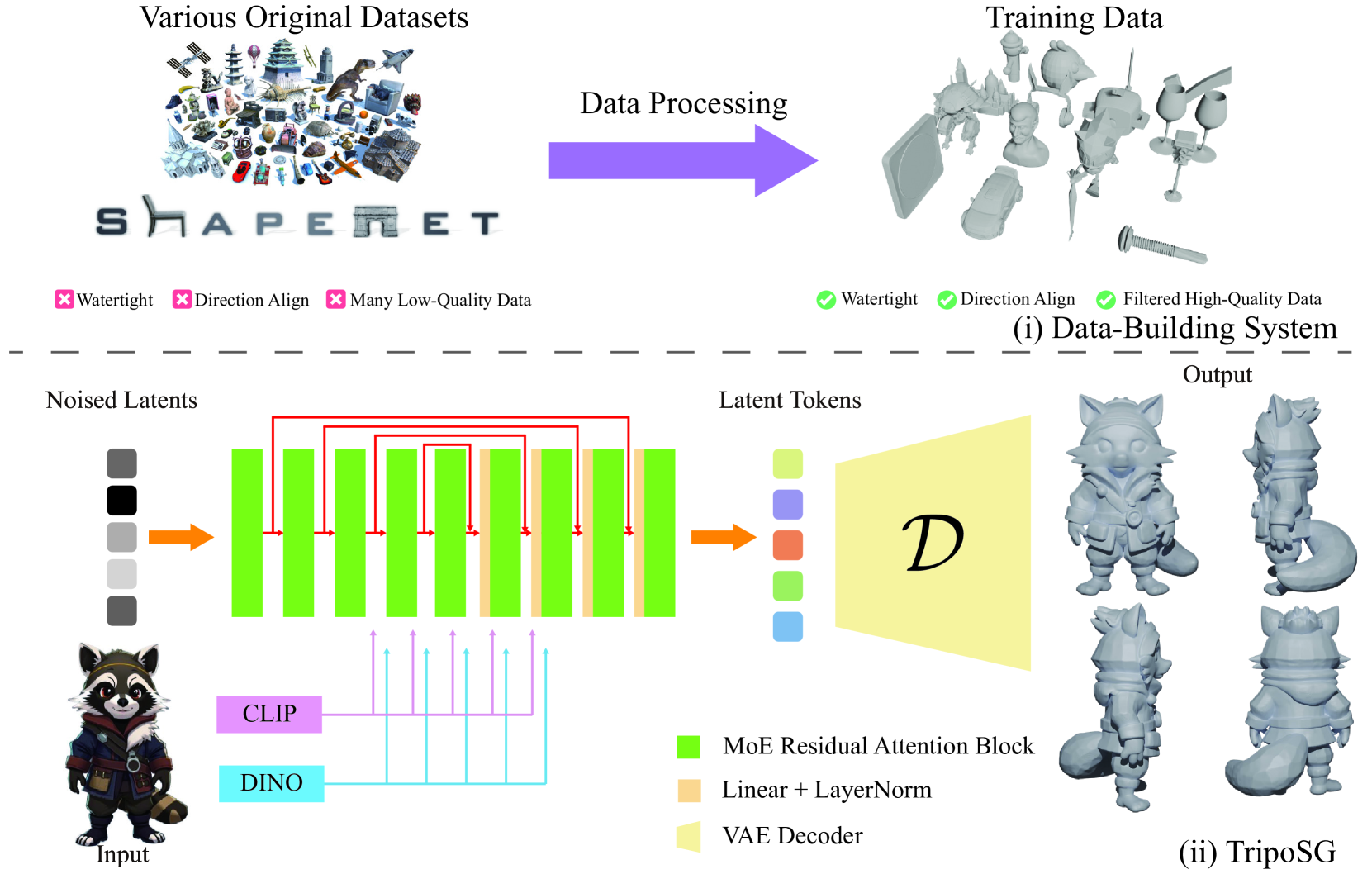 TripoSG系统总览。上半部分是数据构建流水线,下半部分是模型架构。注意两条信息流:CLIP提供语义理解,DINOv2提供局部细节。
TripoSG系统总览。上半部分是数据构建流水线,下半部分是模型架构。注意两条信息流:CLIP提供语义理解,DINOv2提供局部细节。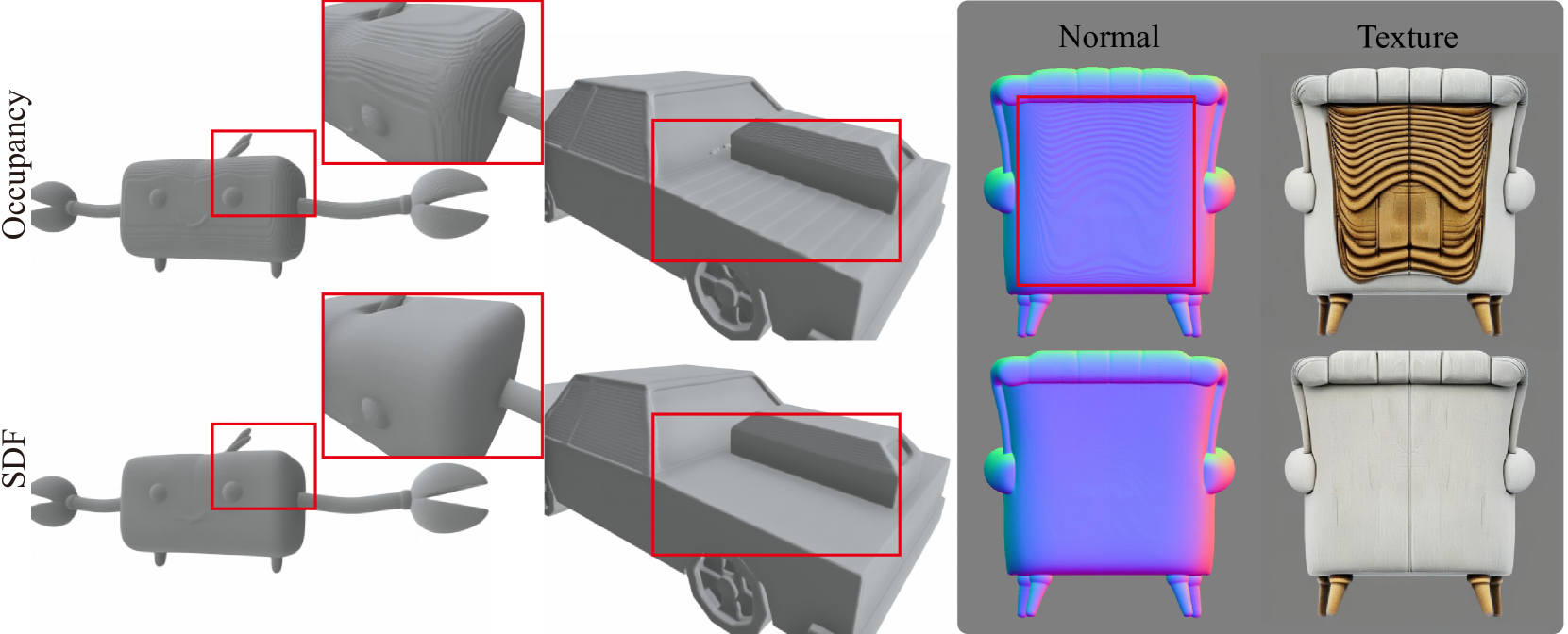 直观对比不同表示和监督方式的重建效果。注意Occupancy的表面锯齿和SDF逐步改进的光滑度。最右列(完整SDF监督)的细节最为丰富。
直观对比不同表示和监督方式的重建效果。注意Occupancy的表面锯齿和SDF逐步改进的光滑度。最右列(完整SDF监督)的细节最为丰富。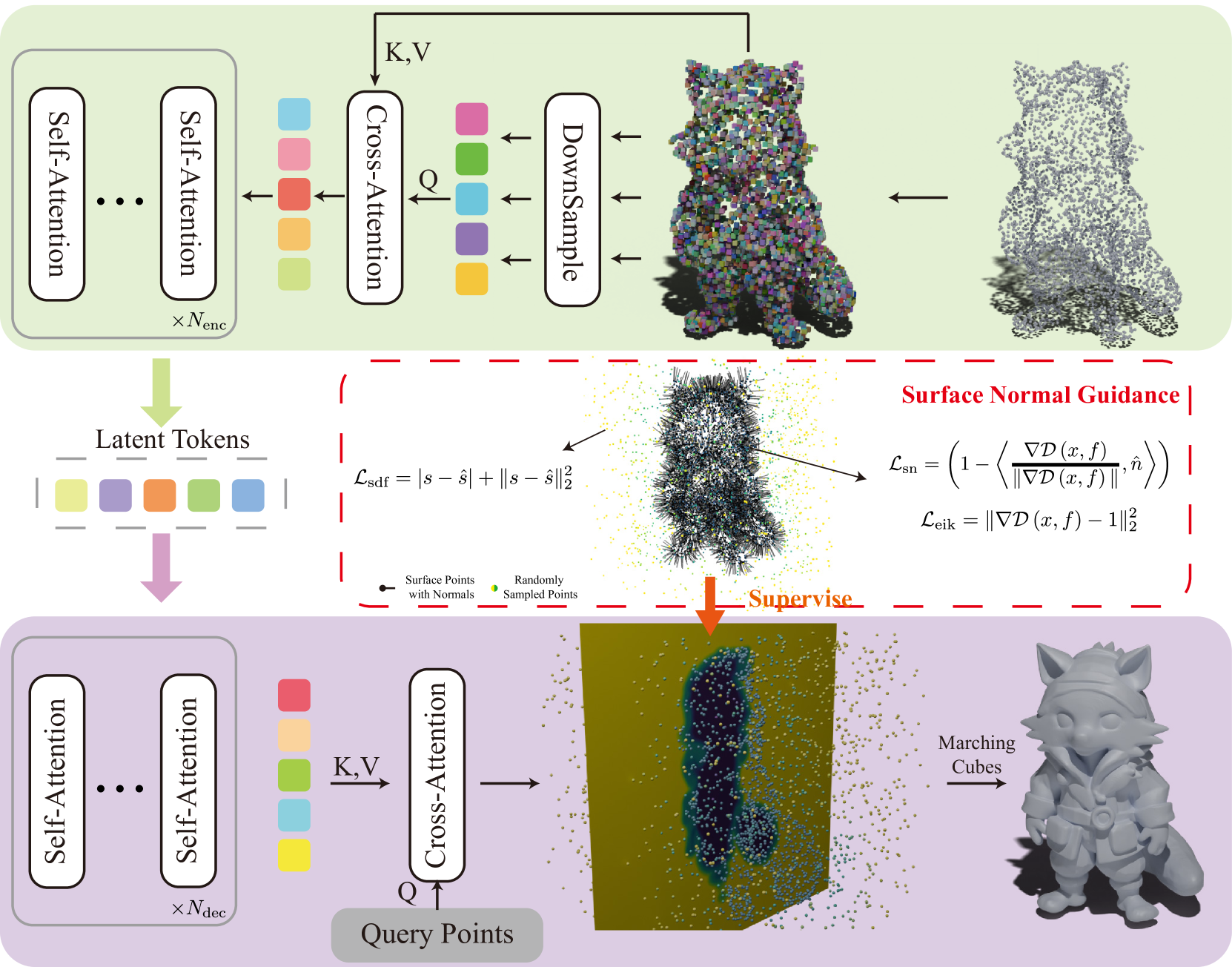 3D VAE架构。编码器(上)将20,480个表面采样点压缩为512/2048个潜在token;解码器(下)接收任意3D查询点,预测其SDF值。注意编码器和解码器之间的层数不对称。
3D VAE架构。编码器(上)将20,480个表面采样点压缩为512/2048个潜在token;解码器(下)接收任意3D查询点,预测其SDF值。注意编码器和解码器之间的层数不对称。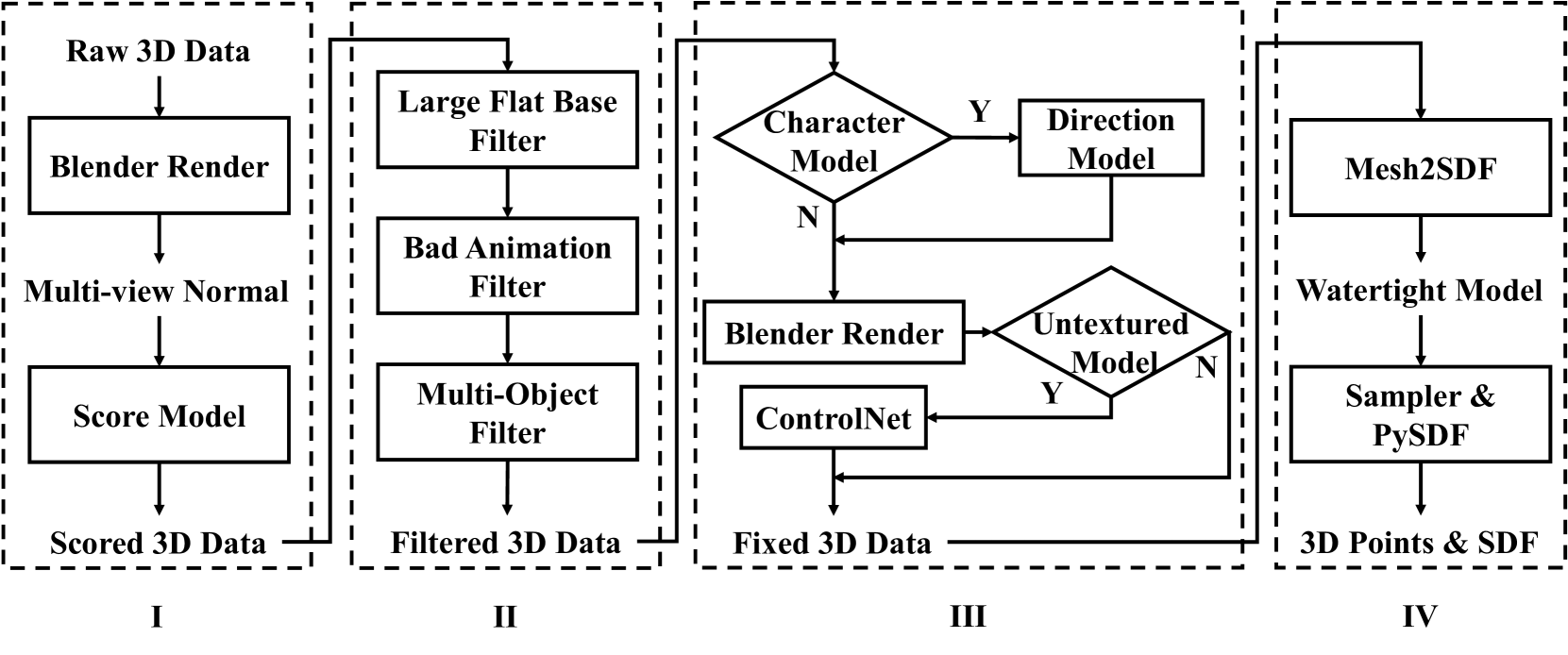 从纯噪声到干净数据的插值路径。DDPM和EDM走弯路,Rectified Flow走直线。直线意味着每一步推理都更高效。
从纯噪声到干净数据的插值路径。DDPM和EDM走弯路,Rectified Flow走直线。直线意味着每一步推理都更高效。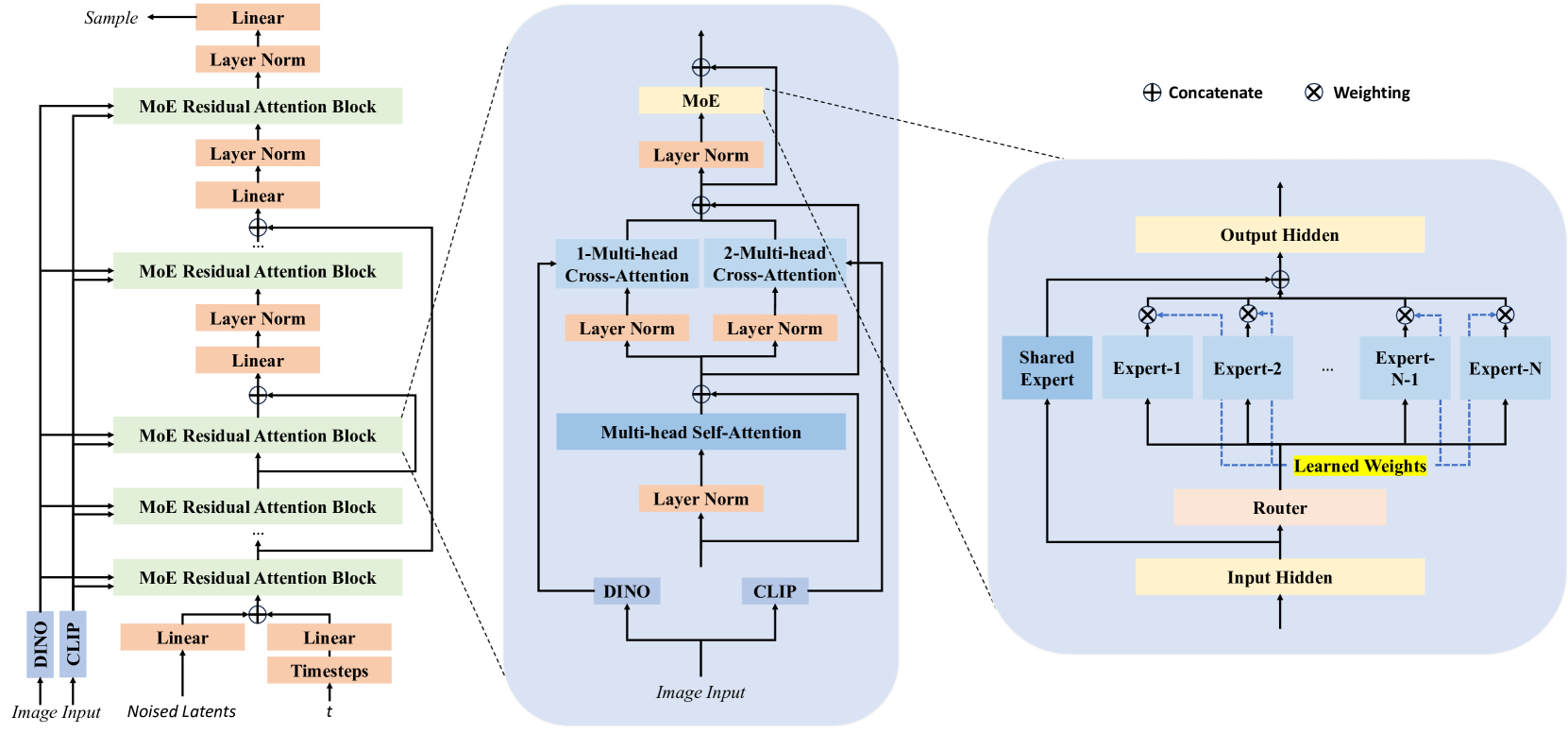 Transformer block的内部结构(中间面板b)。注意两个独立的交叉注意力层——一个接CLIP特征,一个接DINOv2特征。这不是简单拼接,而是让模型在每一层独立地"查阅"语义信息和几何信息。
Transformer block的内部结构(中间面板b)。注意两个独立的交叉注意力层——一个接CLIP特征,一个接DINOv2特征。这不是简单拼接,而是让模型在每一层独立地"查阅"语义信息和几何信息。 数据清洗流水线的四个阶段。注意每个阶段都有具体的质量控制措施。最终从1000万原始数据中筛选出200万高质量训练样本。
数据清洗流水线的四个阶段。注意每个阶段都有具体的质量控制措施。最终从1000万原始数据中筛选出200万高质量训练样本。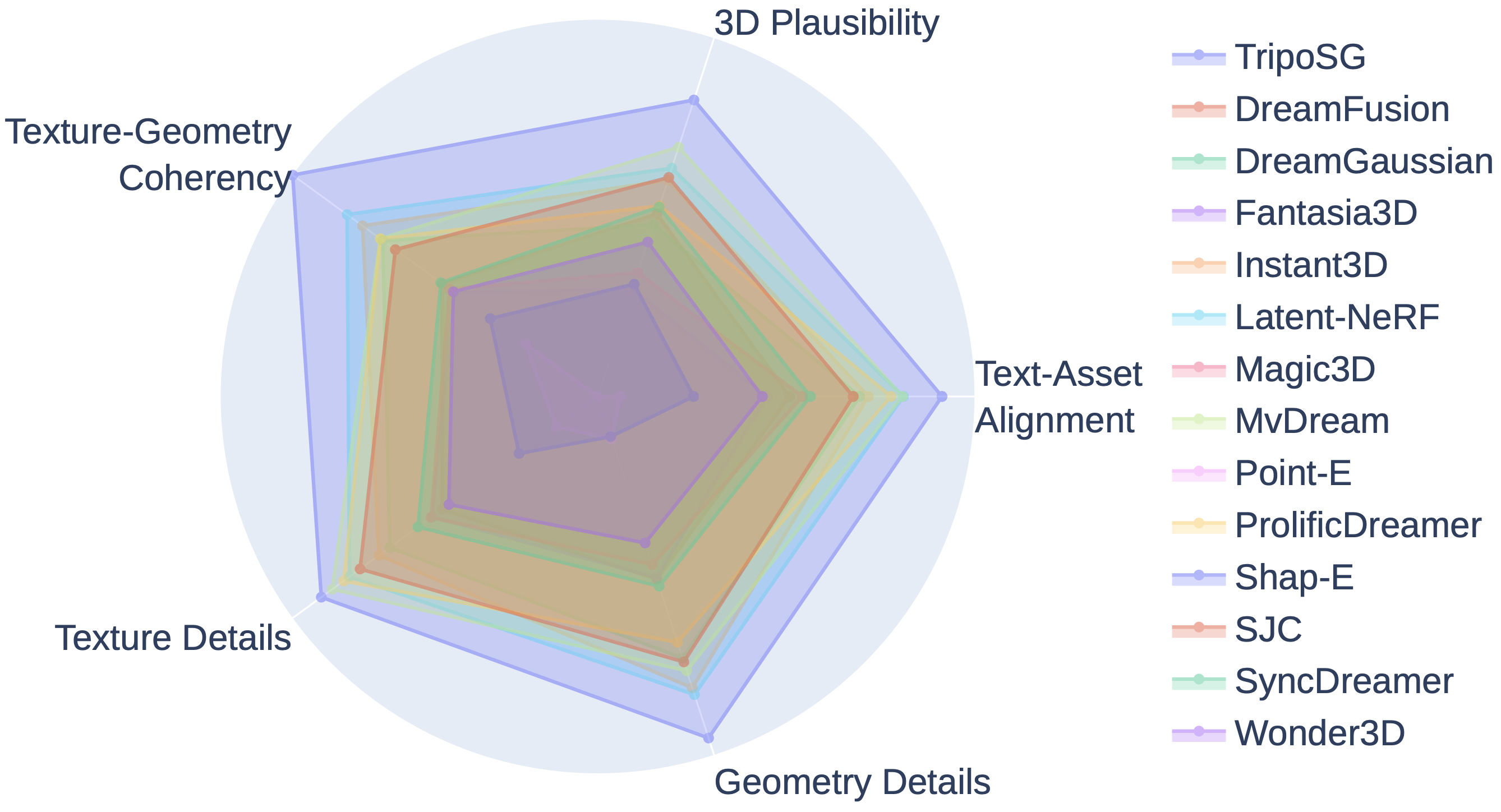 GPTEval3D雷达图。TripoSG(最外圈)在所有5个维度上都达到了最高分:3D合理性、文本对齐、几何细节、纹理细节、纹理-几何一致性。
GPTEval3D雷达图。TripoSG(最外圈)在所有5个维度上都达到了最高分:3D合理性、文本对齐、几何细节、纹理细节、纹理-几何一致性。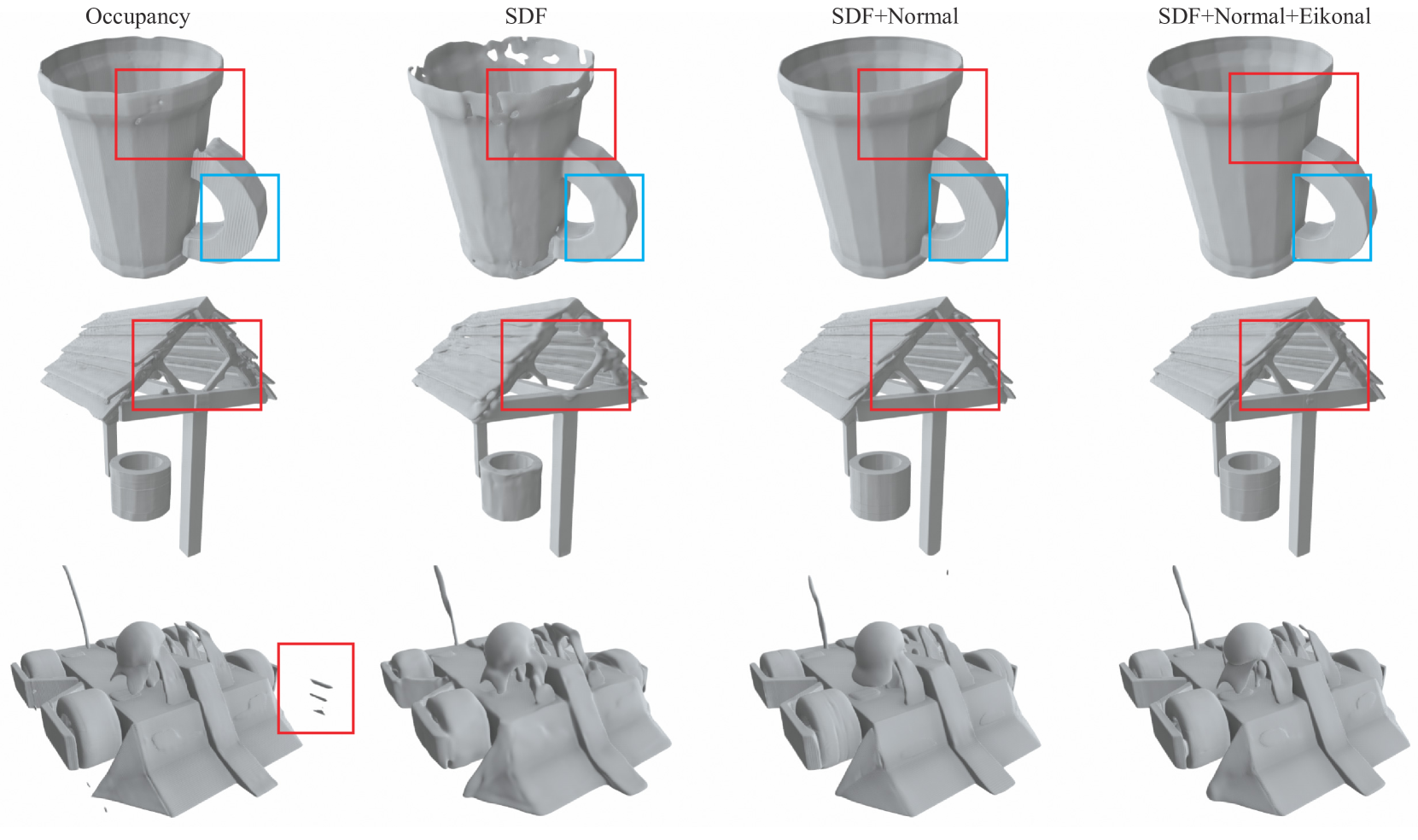 与现有方法的定性对比。注意TripoSG在细节保真度上的优势——衣物褶皱、面部特征、配饰结构都显著优于其他方法。
与现有方法的定性对比。注意TripoSG在细节保真度上的优势——衣物褶皱、面部特征、配饰结构都显著优于其他方法。