一个你可能没想过的问题
你拍了一张杯子的照片。
你能想象出杯子背面长什么样吗?当然能。你的大脑自动补全了看不到的部分——杯柄的弧度、底部的弧线、杯口的厚度。你甚至不需要想,这些信息就"在那里"了。
但对AI来说,这是一个极其困难的问题。
一张2D照片只包含一个视角的信息——大量几何细节被"压扁"了。让机器从一张照片里"想象"出完整的3D形状,相当于让它解一个信息量严重不足的方程。
这就是单图3D重建领域要解决的核心挑战。
2025年初,来自VAST(Tripo的母公司)、香港中文大学、UT Austin和上海AI Lab的团队,发布了TripoSG——一个40亿参数的生成模型,能从单张图片生成高保真3D网格。不是糊成一团的体素块,而是表面光滑、细节丰富的真实网格。
它是怎么做到的?
 TripoSG能处理各种风格的输入——写实照片、卡通角色、概念草图——并生成拓扑完整、细节丰富的3D网格。
TripoSG能处理各种风格的输入——写实照片、卡通角色、概念草图——并生成拓扑完整、细节丰富的3D网格。
先说全景:TripoSG在做什么
在动手拆解技术细节之前,先看清全局。
TripoSG的任务很简单:输入一张图片,输出一个3D网格(mesh)。
但它的实现路径非常优雅,分为两个核心组件:
- 3D VAE:学会把任意3D形状"压缩"成一串紧凑的数字(潜在向量),也能从数字"解压"回3D形状
- Rectified Flow Transformer:学会看一张图片,"想象"出对应的3D潜在向量
先训练VAE,让它学会3D的"语言"。再训练Transformer,让它学会从2D图片"翻译"成3D语言。
最终推理时,图片进去,VAE解码器把Transformer的输出变成3D网格。就这么简单。
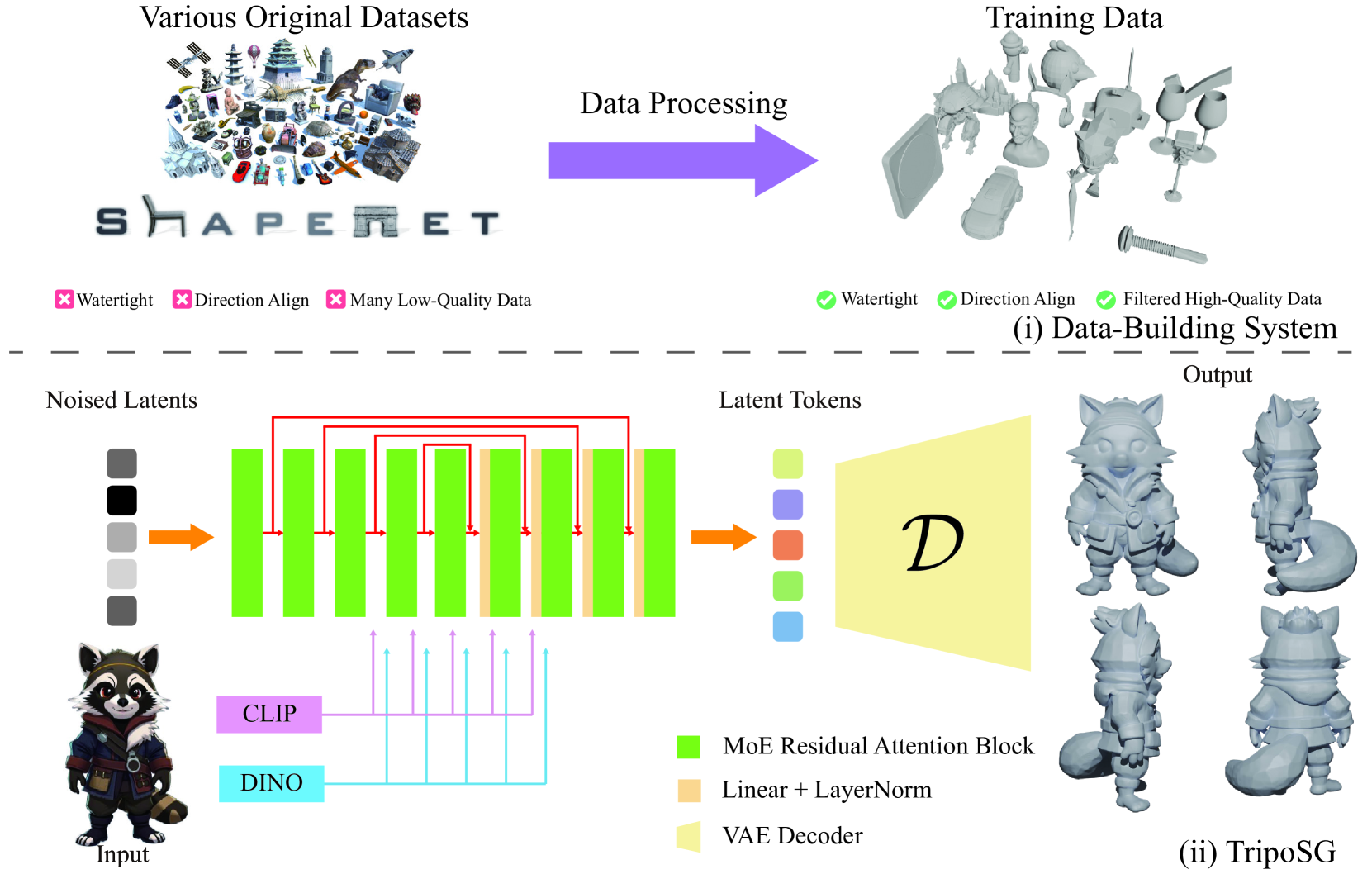 TripoSG系统总览。上半部分是数据构建流水线,下半部分是模型架构。注意两条信息流:CLIP提供语义理解,DINOv2提供局部细节。
TripoSG系统总览。上半部分是数据构建流水线,下半部分是模型架构。注意两条信息流:CLIP提供语义理解,DINOv2提供局部细节。
第一个关键选择:用SDF而不是Occupancy来描述3D
要让AI处理3D形状,首先要选一种"数学语言"来描述它。这个选择至关重要——就像选错了坐标系,后面所有计算都会别扭。
两种语言的对比
Occupancy(占据场):对空间中的每个点,回答"这里有东西吗?"——是或否,1或0。
SDF(Signed Distance Function,符号距离函数):对空间中的每个点,回答"这里离最近的表面有多远?"——如果在物体内部,距离为负;外部为正;表面上为零。
区别在哪?
Occupancy是二元的——非黑即白。想象你用马赛克拼一个圆,边缘一定是锯齿状的。
SDF是连续的——它知道"接近表面"和"远离表面"的区别。同样拼一个圆,SDF能告诉你每个像素离圆边有多远,所以提取出的表面自然就是光滑的。
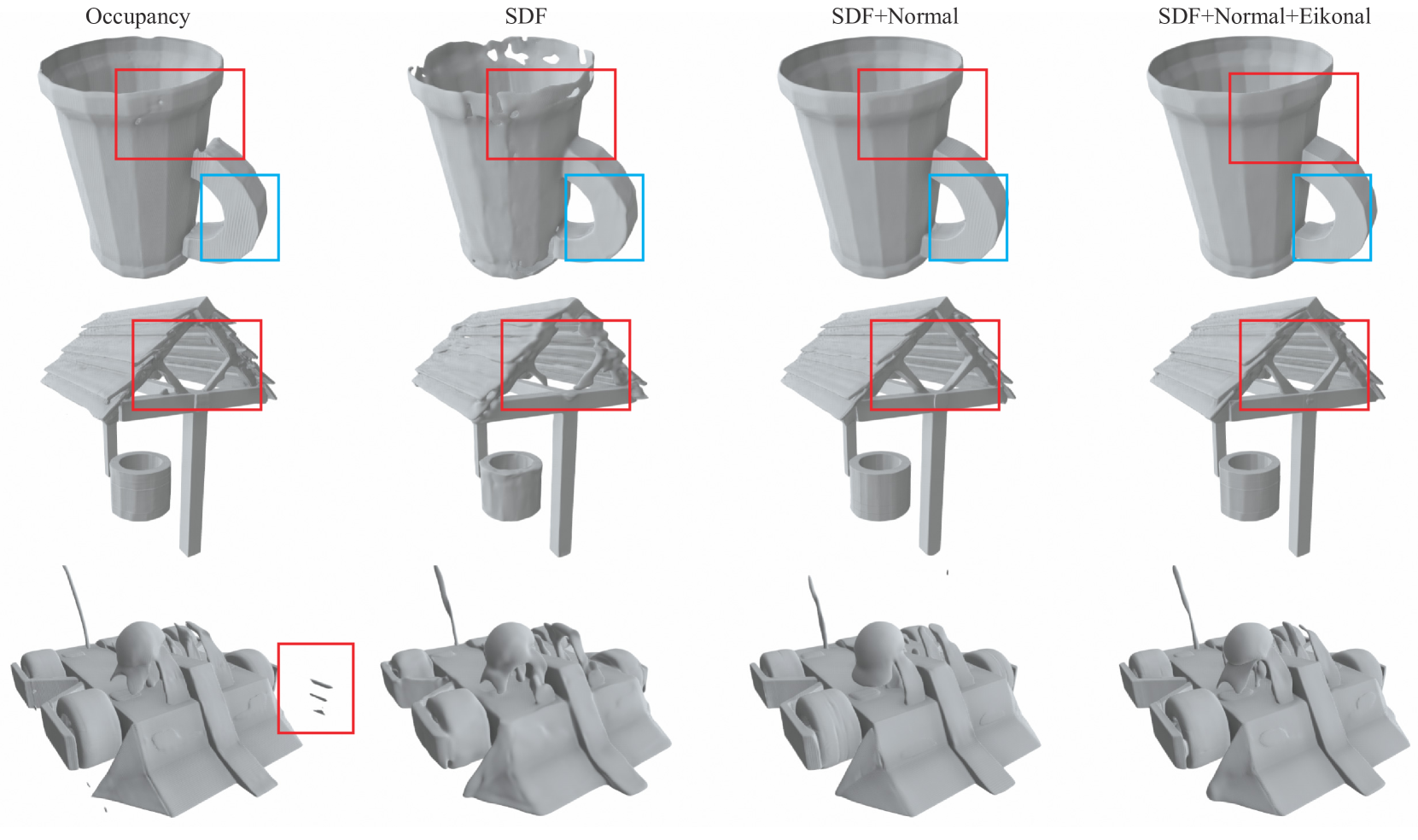
这不是理论上的微小差异。论文的消融实验明确显示:
| 表示方式 | 监督方式 | Chamfer距离 ↓ | F-Score ↑ | 法线一致性 ↑ |
|---|---|---|---|---|
| Occupancy | 交叉熵 | 较高 | 较低 | 较低 |
| SDF | L1+L2 | 中等 | 中等 | 中等 |
| SDF | L1+L2 + 法线 + Eikonal | 4.57 | 0.999 | 0.957 |
SDF加上完整监督,在所有指标上都碾压Occupancy。
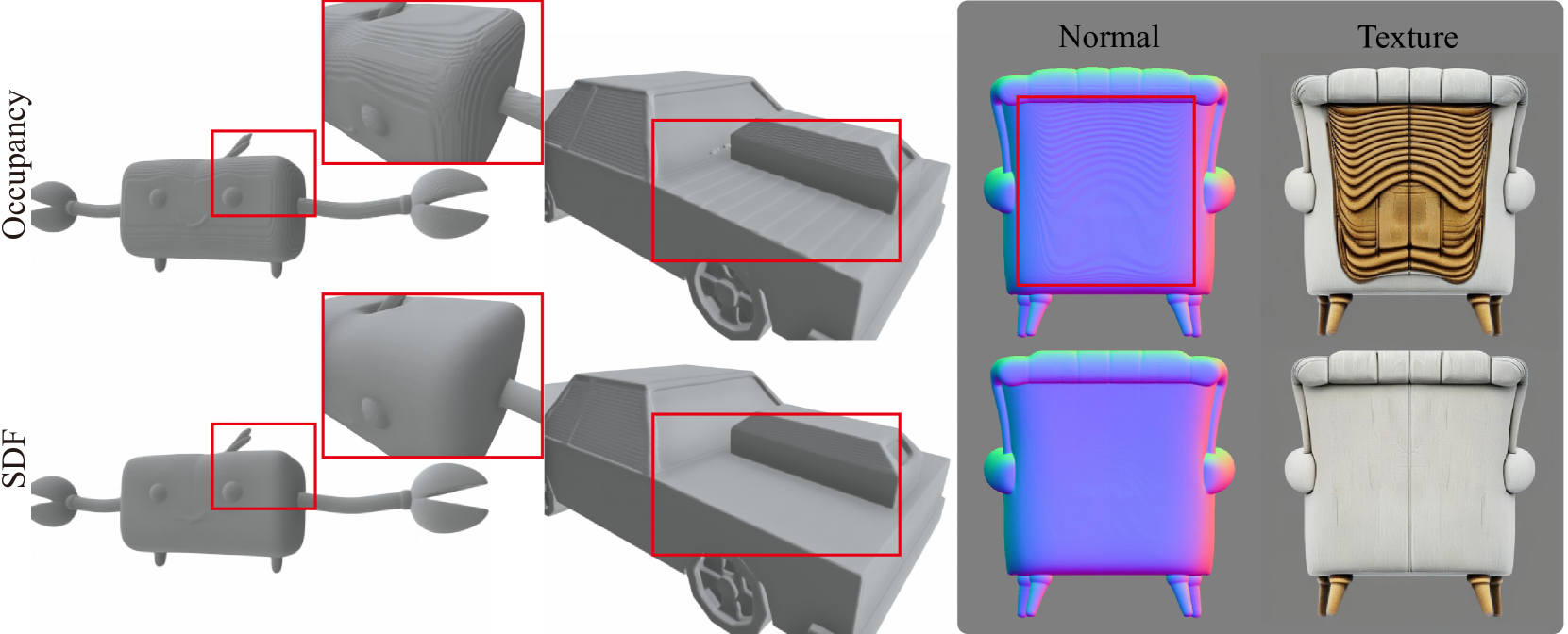 直观对比不同表示和监督方式的重建效果。注意Occupancy的表面锯齿和SDF逐步改进的光滑度。最右列(完整SDF监督)的细节最为丰富。
直观对比不同表示和监督方式的重建效果。注意Occupancy的表面锯齿和SDF逐步改进的光滑度。最右列(完整SDF监督)的细节最为丰富。
三重监督:让SDF学得更好
TripoSG不只用简单的"预测值 vs 真实值"来训练SDF。它用了三种互补的损失函数:
L1 + L2 距离损失:最基本的——预测的距离值要接近真实值。L1管大误差不跑太远,L2管小误差更精确。
法线引导损失(Surface Normal Loss):SDF的梯度方向应该和真实表面法线一致。通俗地说,"距离变化最快的方向"应该正好垂直于表面。这逼迫模型学会精确的表面朝向。
Eikonal正则化:数学上,合法的距离函数必须满足一个性质——梯度的模(大小)处处等于1。你在任何方向走一小步,距离就该变化一小步。这个约束保证SDF场在整个空间内"行为正常",而不只是在训练采样点附近凑合。
\[\mathcal{L}_{\text{vae}} = \mathcal{L}_{\text{sdf}} + \lambda_{sn}\mathcal{L}_{\text{sn}} + \lambda_{eik}\mathcal{L}_{\text{eik}} + \lambda_{kl}\mathcal{L}_{\text{kl}}\]三重监督的效果是递进式的:距离损失确定"大致形状",法线损失雕刻"表面细节",Eikonal正则化保证"全局一致性"。
第二个关键选择:VAE的Transformer架构
TripoSG的VAE不是传统的卷积网络——而是一个非对称Transformer。
为什么用Transformer?
3D形状不像图片那样排列在整齐的网格上。一个杯子和一把椅子的拓扑结构完全不同。Transformer的自注意力机制天然适合处理这种无序的点集——它不在乎点的排列顺序,只关心点与点之间的关系。
非对称设计
编码器只有8层,解码器有16层。为什么?
因为"压缩"和"还原"的难度不对称。把复杂的3D形状压成紧凑的表示,需要的是抽象和归纳,相对简单。从紧凑的表示还原出每一个表面细节,需要的是想象和补全,难度更大。所以解码器要更"大脑"。
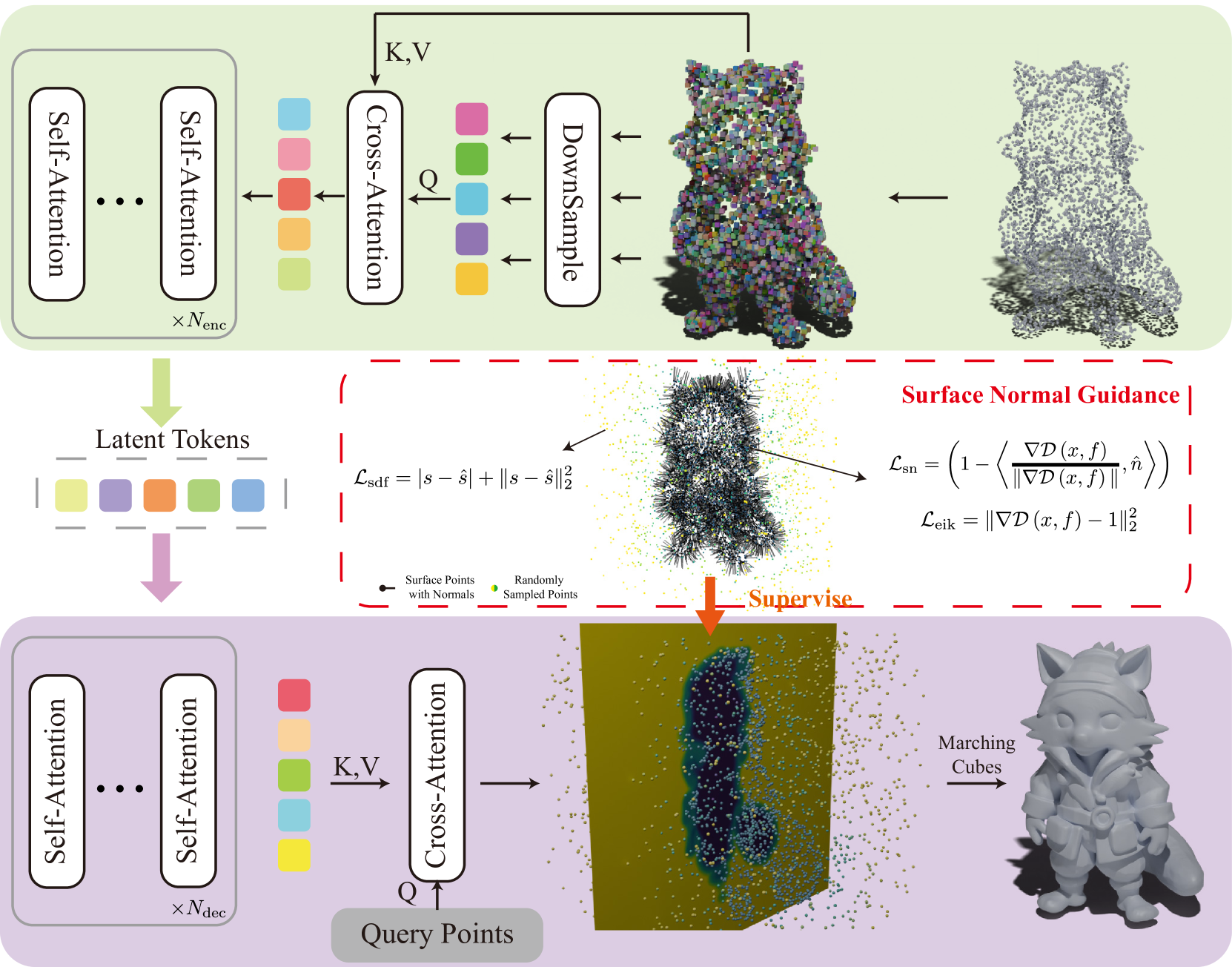 3D VAE架构。编码器(上)将20,480个表面采样点压缩为512/2048个潜在token;解码器(下)接收任意3D查询点,预测其SDF值。注意编码器和解码器之间的层数不对称。
3D VAE架构。编码器(上)将20,480个表面采样点压缩为512/2048个潜在token;解码器(下)接收任意3D查询点,预测其SDF值。注意编码器和解码器之间的层数不对称。
多分辨率训练与外推
训练时,VAE在两个分辨率上交替训练:512个token和2048个token。低分辨率学全局结构,高分辨率学局部细节。
有趣的是,推理时可以外推到4096个token——不需要重新训练。这得益于Transformer对序列长度的天然泛化能力(虽然需要配合时间步移位来保持信噪比一致,后面会讲)。
核心引擎:Rectified Flow Transformer
VAE搞定了3D的"语言",现在需要一个模型来学会"看图说话"——从2D图片生成对应的3D潜在表示。这就是Rectified Flow Transformer的工作。
为什么不用DDPM?
扩散模型有多种"方言"。TripoSG团队比较了三种:
| 方法 | 插值路径 | Normal-FID ↓ |
|---|---|---|
| DDPM | 弯曲路径 | 9.63 |
| EDM | 弯曲路径 | 9.50 |
| Rectified Flow | 直线路径 | 9.47 |
差异不算巨大,但Rectified Flow有一个本质优势:路径是直的。
 从纯噪声到干净数据的插值路径。DDPM和EDM走弯路,Rectified Flow走直线。直线意味着每一步推理都更高效。
从纯噪声到干净数据的插值路径。DDPM和EDM走弯路,Rectified Flow走直线。直线意味着每一步推理都更高效。
通俗理解:想象你要从A点走到B点。DDPM走的是一条弯弯绕绕的曲线——每一步方向都在变,走错一点就偏了。Rectified Flow走的是两点之间的直线——方向明确,即使步子大一点也不容易偏。
这意味着:
- 推理步数更少:直线路径不需要那么多小碎步来保持方向
- 训练更稳定:目标更简单——学会沿直线走就行
- 扩展性更好:更适合大规模模型和高分辨率生成
数学公式也很优美:
\[x_t = t \cdot x_0 + (1-t) \cdot \epsilon\]t=0时是纯噪声,t=1时是干净数据,中间就是二者的线性混合。模型要学的就是:给定任意中间状态 $x_t$,预测从噪声到数据的"速度向量"。
双编码器条件注入:CLIP + DINOv2
这是TripoSG最精巧的设计之一。
单靠一个图像编码器不够。为什么?因为从图片中提取的信息有两个维度:
- 语义维度:这是什么东西?一把椅子?一只猫?风格是写实还是卡通?
- 几何维度:表面纹理如何?边缘在哪里?细节结构是什么样的?
TripoSG的答案是用两个编码器,各司其职:
CLIP-ViT-L/14 → 提供全局语义理解。CLIP是在图文对上训练的,所以它"懂"图片在说什么——对象类别、风格、场景意图。
DINOv2-Large → 提供局部几何细节。DINOv2是自监督训练的视觉基础模型,擅长捕捉局部纹理、边缘和空间结构。
在Transformer的每一个block中,两种特征通过独立的交叉注意力层注入:
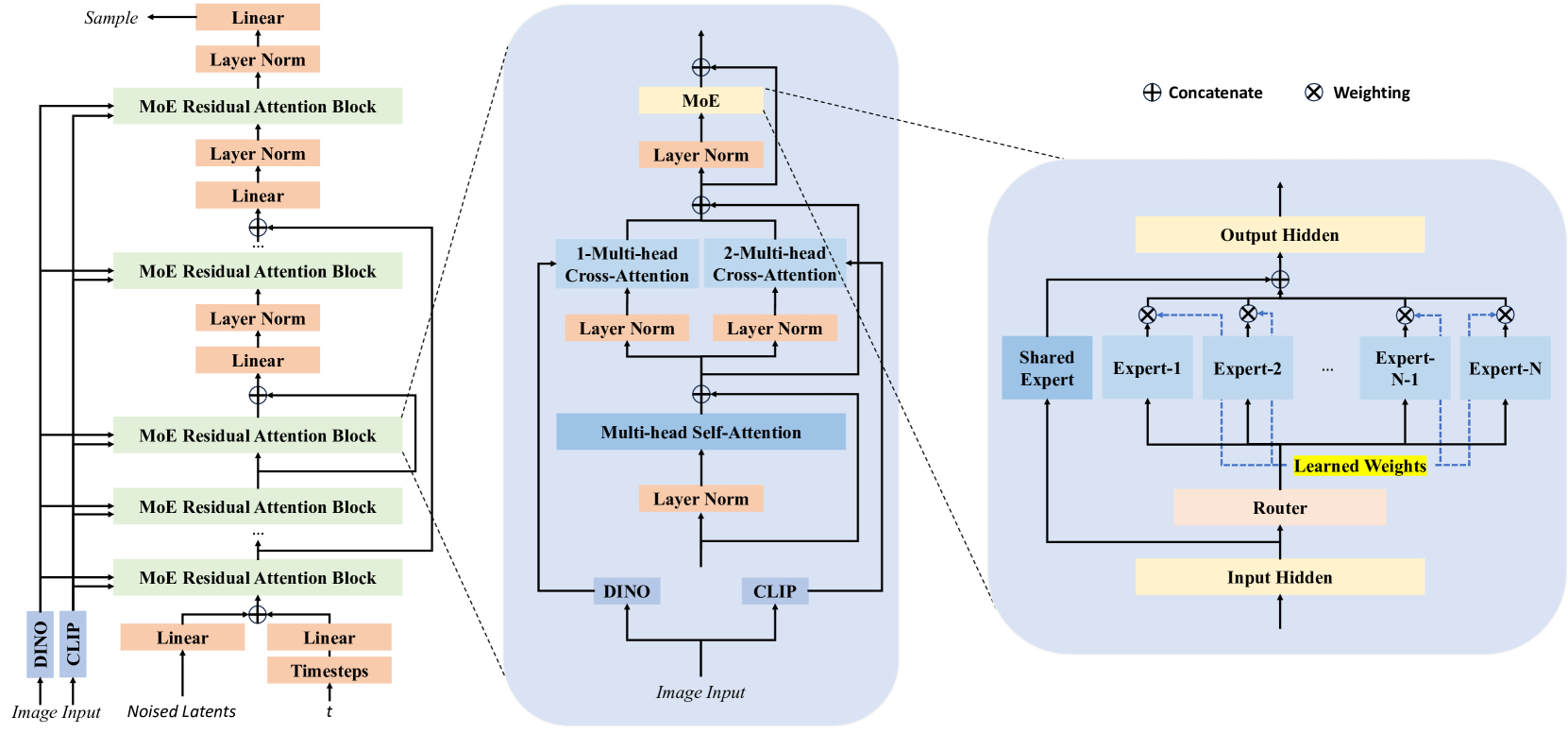 Transformer block的内部结构(中间面板b)。注意两个独立的交叉注意力层——一个接CLIP特征,一个接DINOv2特征。这不是简单拼接,而是让模型在每一层独立地"查阅"语义信息和几何信息。
Transformer block的内部结构(中间面板b)。注意两个独立的交叉注意力层——一个接CLIP特征,一个接DINOv2特征。这不是简单拼接,而是让模型在每一层独立地"查阅"语义信息和几何信息。
消融实验证实了双编码器的价值:只用DINOv2时Normal-FID为10.69,加上CLIP后降到9.47——提升显著。
Skip Connection:借鉴U-Net的智慧
TripoSG的Transformer采用了一个关键设计:编码器-解码器之间的跳跃连接。
结构是10层编码器 + 1层中间层 + 10层解码器 = 21个Transformer block。编码器第i层的输出直接加到解码器第(N-i)层的输出上:
\[Z_{DB}^{(N-i)} = DB^{(N-i)}(Z_{DB}^{(N-i-1)}) + EB^{(i)}(Z_{EB}^{(i-1)})\]这和U-Net的设计思想完全一样:浅层保留细节(高频信息),深层捕获语义(低频信息),跳跃连接让两者融合。
在消融实验中,跳跃连接的贡献是所有架构改进中最大的。
Logit-Normal时间步采样
训练时,不同的时间步(噪声程度)难度不同。t接近0或1时(接近纯噪声或纯数据),模型"猜"起来比较容易。最难的是中间地带——半噪声半信号,模型需要在模糊中找到结构。
TripoSG用logit-normal分布来采样时间步,让训练重点集中在这些"困难"的中间阶段:
\[\pi_{\text{ln}}(t; m, s) = \frac{1}{s\sqrt{2\pi} \cdot t(1-t)} \exp\left(-\frac{(\log \frac{t}{1-t} - m)^2}{2s^2}\right)\]效果:更多的训练算力花在最需要学习的地方。
MoE:用40亿参数但不多花推理成本
模型大了效果好,这不是新闻。但模型大了推理也慢——这是问题。
TripoSG的解决方案是Mixture of Experts (MoE,混合专家)。
核心思想:把一个大的FFN层拆成8个"专家",每次推理时只激活其中2个。这样参数总量是40亿,但实际计算量接近15亿——参数多了2.5倍,速度几乎没变。
具体实现:
- 只在最后6个解码器层使用MoE
- 每层8个专家FFN + 1个共享专家(所有token都经过)
- Top-2路由:每个token动态选择2个最相关的专家
- 辅助负载均衡损失:防止所有token都挤到同一个专家
这不是随意的选择。MoE放在解码器后半部分,因为那里负责生成最细致的几何细节——正是需要"专业分工"的地方。
数据:最重要的一环
论文里最让人震撼的一个数字:数据从18万扩到200万后,Normal-FID从7.94降到3.36。
这个提升幅度远超所有架构改进之和。换句话说,你可以把架构做得很精巧,但如果数据不够好不够多,都是白搭。
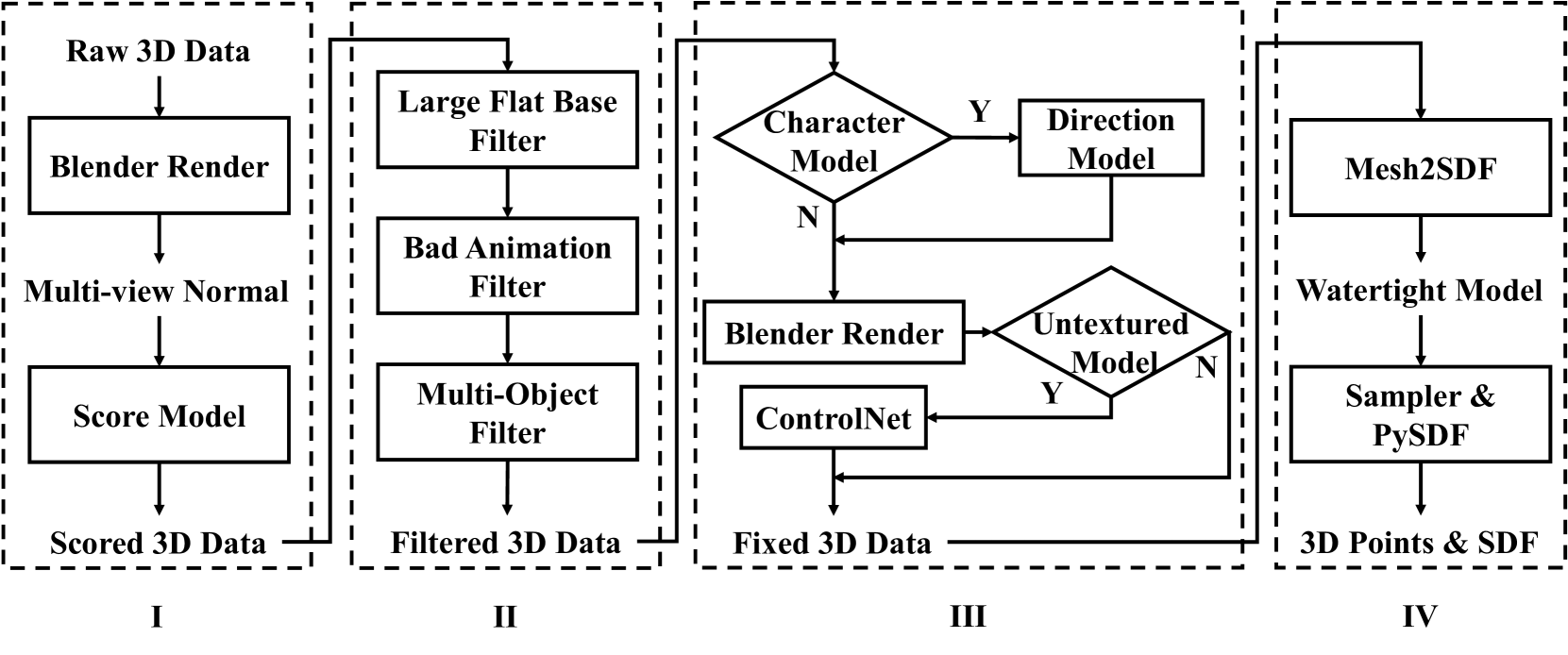
四阶段数据流水线
TripoSG从Objaverse-XL和ShapeNet收集了约1000万个原始3D模型。但绝大多数质量堪忧——破面、翻面、多物体堆叠、没有纹理的光秃秃几何体。怎么办?
 数据清洗流水线的四个阶段。注意每个阶段都有具体的质量控制措施。最终从1000万原始数据中筛选出200万高质量训练样本。
数据清洗流水线的四个阶段。注意每个阶段都有具体的质量控制措施。最终从1000万原始数据中筛选出200万高质量训练样本。
阶段一:评分
请20位专业3D建模师手动给约1万个参考模型打分(1-5分)。然后训练一个简单的线性回归模型——输入是CLIP+DINOv2特征(从多视角法线图提取),输出是质量分数。用这个自动评分器给所有1000万个模型打分。
这个方法很聪明:用少量人工标注训练自动评分器,然后规模化。
阶段二:过滤
- 删除带大平面底座的模型(通过表面patch分类)
- 排除有动画渲染错误的模型
- 过滤多物体堆叠(通过连通分量分析)
阶段三:修复和增强
- 朝向校正:角色模型可能面朝任意方向。用24个候选朝向渲染6视图,训练DINOv2分类器选最正确的
- 纹理生成:对没有纹理的模型,用ControlNet++从多视角法线图生成RGB纹理
阶段四:SDF场生产
- 非水密网格通过UDF(无符号距离场)在 $512^3$ 体素网格上转换为水密网格
- Marching Cubes提取等值面
- 环境遮挡过滤去除内部结构
- 采样表面点、近表面点和随机体积点,配上法线
最终:1000万 → 200万高质量3D对象,每个都配有图像和SDF场数据。
渐进式训练:小步快跑
TripoSG不是一上来就训练40亿参数的4096-token模型。它分三个阶段:
| 阶段 | 分辨率 | 参数 | 学习率 | 步数 | 数据量 |
|---|---|---|---|---|---|
| 1 | 512 tokens | 15亿 (Dense) | 1e-4 | 70万 | 200万 |
| 2 | 2048 tokens | 15亿 (Dense) | 5e-5 | 30万 | 200万 |
| 3 | 4096 tokens | 40亿 (MoE) | 1e-5 | 10万 | 100万(精选) |
第一阶段学全局结构,第二阶段学局部细节,第三阶段上MoE并在最高分辨率上精调。
注意第三阶段只用了100万数据——这是200万中进一步精选的高质量子集。在最精细的分辨率上,数据质量比数量更重要。
总计算量:160块A100 GPU,约3周。
分辨率移位:一个被低估的技巧
切换分辨率时,信噪比会变。512个token时的"30%噪声"和4096个token时的"30%噪声"含义不同——token越多,每个token携带的信息越少,同等噪声级别下信号衰减得更厉害。
TripoSG用一个简单的移位公式来补偿:
\[t_m = \frac{\sqrt{m/n} \cdot t_n}{1 + (\sqrt{m/n} - 1) \cdot t_n}\]其中m是当前分辨率,n是基准分辨率。这保证了不同分辨率下噪声调度的等效性。
实验结果:全面领先
定量评估
TripoSG提出了一个新的评估指标Normal-FID:从相同视角渲染生成模型和真实模型的法线图,计算FID。这个指标专门度量几何质量,不受纹理干扰。
消融实验的全景:
| 配置 | Normal-FID ↓ |
|---|---|
| 只用DINOv2,无skip connection | 10.69 |
| CLIP+DINOv2,DDPM | 9.63 |
| CLIP+DINOv2,EDM | 9.50 |
| CLIP+DINOv2,Rectified Flow | 9.47 |
| 512 tokens | 9.47 |
| 2048 tokens | 8.38 |
| 4096 tokens | 8.12 |
| 4096 tokens + MoE (40亿参数) | 7.94 |
| 完整TripoSG (200万数据) | 3.36 |
读这个表的方式:从上到下,每一行都是在上一行基础上做了一个改进。最后一行的飞跃(7.94 → 3.36)来自数据量的扩大——这是全表中最大的单项提升。
GPTEval3D:多维度AI评估
论文还使用了基于大语言模型的评估(用Claude 3.5 Sonnet打分),从5个维度综合评判:
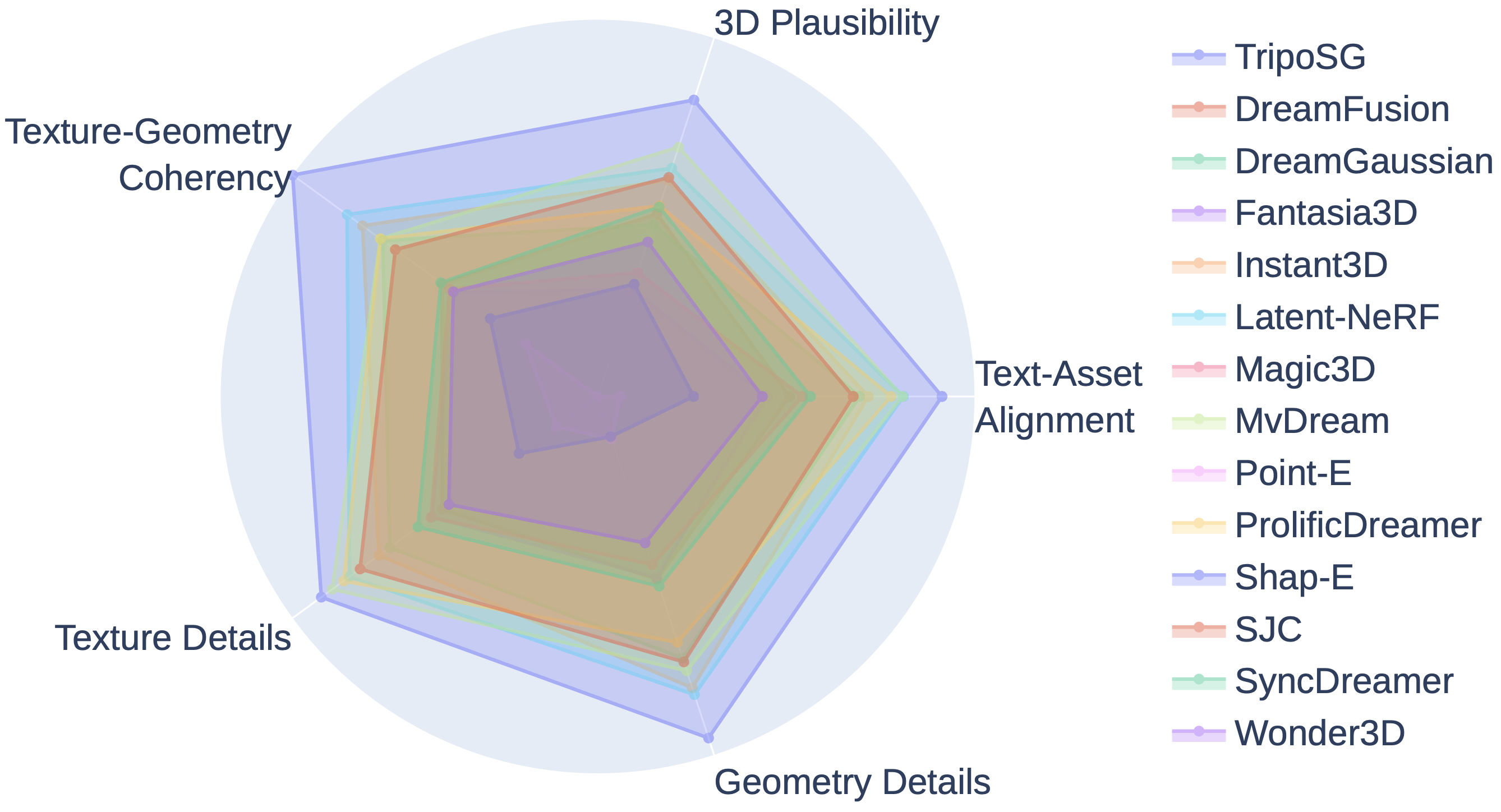 GPTEval3D雷达图。TripoSG(最外圈)在所有5个维度上都达到了最高分:3D合理性、文本对齐、几何细节、纹理细节、纹理-几何一致性。
GPTEval3D雷达图。TripoSG(最外圈)在所有5个维度上都达到了最高分:3D合理性、文本对齐、几何细节、纹理细节、纹理-几何一致性。
定性对比
和现有方法的直接比较更为直观:
 与现有方法的定性对比。注意TripoSG在细节保真度上的优势——衣物褶皱、面部特征、配饰结构都显著优于其他方法。
与现有方法的定性对比。注意TripoSG在细节保真度上的优势——衣物褶皱、面部特征、配饰结构都显著优于其他方法。
技术洞察:TripoSG教给我们什么
1. 数据 > 架构
这是TripoSG最重要的教训。所有架构改进加在一起(双编码器、skip connection、rectified flow、MoE)把Normal-FID从10.69降到7.94——改善了约26%。而数据从18万扩到200万,直接把7.94降到3.36——改善了58%。
这不是说架构不重要。没有好的架构,模型连18万数据都学不好。但它提醒我们:在架构已经"够用"之后,数据质量和规模才是真正的天花板。
2. SDF是3D生成的正确语言
Occupancy场的二值性从根本上限制了表面质量。SDF加上梯度域监督(法线+Eikonal),提供了一种既精确又稳定的3D表示。这可能会成为后续3D生成工作的标准选择。
3. 稀疏MoE是缩放3D模型的高效路径
从15亿到40亿参数,MoE只增加了约10%的推理开销。这种"参数多但计算少"的scaling策略特别适合3D生成——因为3D推理本身就很重(要查询大量3D点),参数扩展如果同步带来计算暴增是不可接受的。
4. 渐进式训练是实际可行的唯一路径
直接在最高分辨率(4096 tokens)上从头训练40亿参数模型,在当前的硬件条件下几乎不可行。渐进式策略——先低分辨率小模型,再高分辨率大模型——是工程上的必然选择。这也是大模型训练(LLM、图像生成)中反复验证过的经验。
TripoSG之后:3D生成的下一步
TripoSG解决了"从单张图片生成高质量3D几何"的问题,但3D生成领域还有几个重要的开放方向:
纹理与材质:当前的3D生成模型(包括TripoSG)在几何上已经很好,但纹理生成仍然依赖后处理流水线(如多视角纹理投影)。端到端生成几何+纹理仍是活跃的研究方向。
物理属性:游戏和仿真需要的不仅是"看起来像"——还要质量、摩擦系数、弹性模量。这需要更丰富的3D表示。
可编辑性:生成的3D资产需要能被艺术家修改。当前的隐式表示(SDF/NeRF)在可编辑性上远不如传统的多边形建模。这是实际应用中的主要瓶颈。
多视角一致性:从不同角度看,生成的3D模型应该和所有可用的参考图一致。单图输入的信息不足问题,可能需要结合视频输入或多图输入来进一步缓解。
总结
TripoSG的核心贡献,用一句话概括:
用Rectified Flow在SDF潜在空间上做生成,配合CLIP+DINOv2双条件注入和MoE稀疏扩展,加上200万高质量3D数据,实现了单图到高保真3D网格的SOTA生成。
但如果只记住一件事,那就是:
在3D生成这个领域,200万精心策展的数据比任何架构创新都重要。
这与Sutton的"苦涩教训"一脉相承——长期来看,利用计算和数据的通用方法,总会胜过精巧的手工设计。TripoSG的架构确实精巧,但它最大的护城河,是那条从1000万原始数据中淬炼出200万高质量样本的数据流水线。
论文链接:TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
代码开源:github.com/VAST-AI-Research/TripoSG(MIT License)
在线体验:Hugging Face Space